
文|阿尔法工场
当下的大模型赛场,随着最初的热潮褪去,不少VC和投资人对大模型已经进入了一个冷静期,其投资标准,也变得理性、严谨了许多。
既然如此,那么这一阶段能得到明星资本青睐的团队,都具有哪些特征呢?
如前段时间,突然发布自身产品的神秘创业公司——月之暗面Moonshot AI,就给我们提供了一个参考。
在自身的大模型 Kimi Chat发布前,很少有人会想到,这个创始人仅31岁,且没有任何产品发布的AI初创企业,会获得红杉中国和真格基金等 VC 的投资,并被The Information 选为五家「中国 OpenAI」的创业公司之一。
那么,对国内大模型而言,月之暗面的入局,究竟是又一场讲故事的炒作,还是一匹赫然出世的黑马?
01 VC们的考虑
现阶段,要拿捏一个AI初创企业的含金量,除了企业公开展示的信息外,从VC们的角度倒推回去,分析其投资的理由,也是一种值得借鉴的思路。
以投资了月之暗面的明星资本红杉中国为例,目前红杉中国在AI领域已经已投资了近 30 家企业,但其真正的核心标准只有两个:1、有使用场景,解决实际问题;2、系统能够持续不断获得有用的数据自我学习来提升处理能力。
在第一条标准上,红衫中国对AI企业的筛选,有着与国内大多数VC不同的洞见。
当前,AI 投资大多集中在 B 端,因为相较于C端,B端的行业垂直类大模型更好找到应用场景。
然而,红衫中国却认为,垂直行业背景不是必备条件,而对行业痛点的深刻洞察,则是更为重要的因素。
比如摩拜创始人不是做自行车的,但是她发现了实实在在的需求,并且意识到在这个过程中 AI 能够发挥价值。
按照这样的思路,来看月之暗面的情况,我们就会理解红衫中国投资的理由。
在月之暗面发布的大模型Kimi Chat,是首个支持输入 20 万汉字的智能助手产品。这一上下文长度,是目前最高的 Claude 2-100k(约 8 万字)的 2.5 倍,GPT-4-32k(约 2.5 万字)的 8 倍。
超长的文本输入,意味着什么?
在Kimi Chat发布前,大模型落地的一个最大阻碍或瓶颈,正是输入长度的限制。
由于长度所限,任何需要进行长篇分析或持续对话的场景,现有的大模型都难以胜任。
例如,在法律行业中,有时从业者需要处理大量的长文本,例如法律文件、合同、判决书、案例等,而在媒体行业中,编辑或撰稿人,也需要对大量的文章、新闻、报道进行分析阅读。
诚然,面对输入长度的限制,人们可以用“分段发送”这种投机取巧的方式规避,然而,由于长度所限,在达到字数限制后,大模型仍然必须对每段内容重新开始分析。
而这种不断“从头开始”的情况,也使大模型难以形成一套连贯的、有深度的见解。
这样的情况,就像是一个原始人,虽然学会了写字,但却因文字载体(只能刻在石头上)所限,无法保存更多的信息,积累更多的智慧,于是文明便无法长远地发展。
而大模型要想摆脱这样的“原始阶段”,向更广阔的场景扩展,文本长度的限制是一定要突破的。
也正因如此,抓住了“长度限制”这一痛点的月之暗面,才会如此得到红衫中国的重视。
然而,除了具体的场景、技术之外,“人”的因素,在大模型创业过程中同样不可忽视。
02 技术天才的前路
当下,几乎每个AI初创企业都想成为OpenAI,但又有多少团队具备那样的人才配备,以及能让其充分发挥自身才干的土壤呢?
从表面上看,在目前的大模型创业热潮中,名校毕业、大厂经验、浓厚的技术基因,似乎已经成了一种“标配”
月之暗面的情况也是如此。
其创始人杨植麟,不仅出身清华,深造于卡内基梅隆大学,后来又效力于谷歌大脑研究院和Meta(Facebook)人工智能研究院,并且还曾与图灵奖得主杨力昆(Yann LeCun)合作发表论文。
同样的,身为团队第二大股东的周昕宇,也是杨植麟清华大学计算机科学与技术系的同学;
而第三大股东吴育昕,毕业于清华大学与卡耐基梅隆大学,曾获2018年欧洲计算机视觉会议(ECCV)最佳论文提名。同时也是Meta(Facebook)人工智能实验室FAIR团队的一员。
从人员构成上看,这是一个技术基因颇为浓厚的团队。
然而,在当下的国内大模型赛场上,明星般的技术人才很多,可真正做出突出成就的,却仍是凤毛麟角。
原因何在?
从OpenAI、Midjorney等成功团队的案例中,我们至少可以总结出两点:1、团队对自身“独立性”的坚持;2、创始人的视野、经验是否开阔;
关于第一点,就国内的情况而言,尽管“技术天才”创业的案例已不在少数,但其中相当一部分团队,由于缺乏股权或经济上的独立性,最终被收购、控股,如之前被光年之外收购的一流科技就是这样的例子。
而相较之下,OpenAI、Midjorney在融资、股权问题上,则有着更为独立的自主权。
身为非盈利性组织的OpenAI,不用总是将股东的意志放在第一位;而Midjorney的创始David Holz,更是凭借着自身的名气与人脉,在不融资的情况下就集齐了相应的资源、人才。
凡此种种,都使其更易于坚持自身独立的研究方向。
而在这方面,根据天眼查App信息显示,月之暗面由杨植麟持股78.97%,拥有绝对控制权。

除了对“独立性”的坚持外,创始人的视野和实践经验,也成了大模型团队成败的另一大因素。
因为技术型团队,虽然对研究有着纯粹的热忱,但有时候,这样的执着却会“剑走偏锋”,陷入一种误入歧途的窘境。
在当下AI的发展方向中,存在着许多不同的路径,有些是有前景的、靠谱的,有些则是需要排除的“错误选项。”
而唯有与国外一流的高校、机构和企业进行广泛交流,并亲自参与实践,才能从中得出正确的、具有前瞻性的判断。

说回到月之暗面,在视野与实践经验方面,杨植麟曾效力于谷歌大脑研究院和Meta(Facebook)人工智能研究院,是Transformer-XL和XLNet的第一作者。
其中,XLNet模型曾在18项自然语言任务中取得了好于谷歌BERT的效果,是当时NLP领域热门的国际前沿模型之一。
这样开阔和前沿的履历,确保了作为创始人的杨植麟,在技术方向的把握上,保持了与国际一线人才相近的水准。
03 “局部胜利”的含金量
在目前月之暗面公布的信息中,其最为人称道的一点,就是推出了首个支持输入20万汉字的大模型Moonshot,以及搭载该模型的智能助手产品Kimi Chat。其文本长度是GPT-4-32k(约 2.5 万字)的 8 倍。
可以说,这是国内在局部领域对GPT-4等先进模型取得的又一场“胜利”。
为什么说“又”呢?
因为此前已经有不只一个国产大模型,宣称自己在某些方面“超越”了GPT-4。
9月,学术界当红开源评测榜单C-Eval最新一期排行榜中,云天励飞的大模型“云天书”排在第一,而GPT-4仅名列第十。
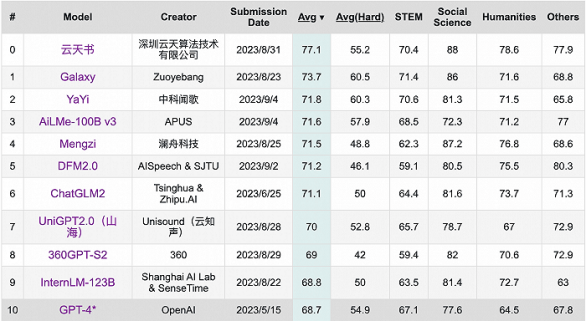
之所以会出现这样诡异的现象,是由于部分国产大模型,学会了一些别样的“应试技巧”(例如将测评的答案抠下来训练),才造成了如此奇观。
其实,从OpenAI的经验来看,一种真正的技术上的“局部胜利”,应该是对AI某一领域天花板的突破,而不是呈一时的数据英雄。
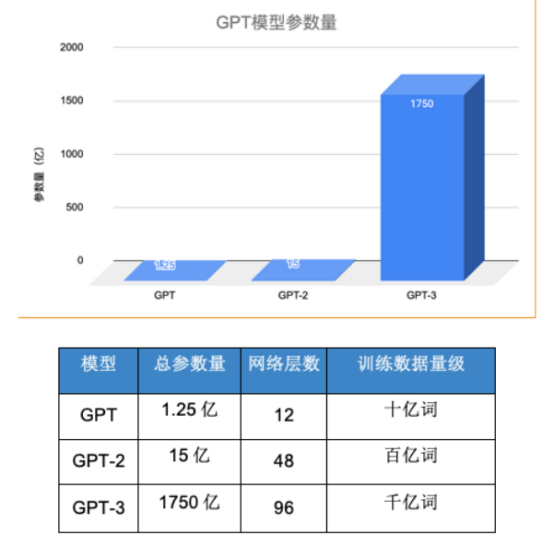
这也是为什么,当年GPT-1被谷歌的BERT打得完败,且测评、数据纷纷拉胯的情况下,OpenAI仍然选择大模型,而非小模型的原因。
毕竟,小模型在专业任务上表现虽强,但只要参数无法提升,更强的智能就无法涌现。
同样地,目前月之暗面推出的Moonshot,同样可以看作是对大模型某一“天花板”的突破。
因为在长文本方面,也存在文本长短、注意力和算力类似的“不可能三角”。
这表现为,文本越长,越难聚集充分注意力,难以完整消化;注意力限制下,短文本无法完整解读复杂信息;处理长文本需要大量算力,提高成本。
在这样的不可能三角中,自注意力机制的计算量会随着上下文长度的增加呈平方级增长,比如上下文增加32倍时,计算量实际会增长1000倍。
而计算量的提升,就意味着就不得不消耗更多的算力,而这无疑意味着更高的模型部署成本。
有鉴于此,唯有以长文本技术为突破,人们才能在其通用模型基础上去裂变出N个应用。
现阶段,长文本的“不可能三角”困境或许暂时还无解,但正因如此,攻破这样的“天花板”才真正有其意义和价值。
而所谓中国的OpenAI,或许正是诞生于对这一个个“天花板”的攻克中。
评论