

文 | 娱乐资本论 James
今天半夜2点,OpenAI召开了首届开发者大会。这条新闻在AIGC圈子里受到了非常重点的关注,以至于很多人熬夜等完全程的直播,并且迅速总结出相关要点。这似乎让人想到了好多年前的苹果发布会,颇有所谓“科技春晚”的架势。
一上午过去,关于这次大会发布新品内容的分析也已经够多了,但如你所料,这里面一定充斥着“史诗级更新!”“最强大模型炸场!”“震撼上新!”之类的最高级形容词,对于普通人了解这些新内容真实的意义,以及与自己的关系,少有帮助。
我们娱乐资本论要做的事情很简单,就是解答两个问题:
·本次开发者大会的更新是否显著提升了能力,对文娱、媒体从业者用户有什么帮助?
·这些更新是否拉大了ChatGPT与国内友商之间的差距,“赶上或超越GPT”是不是更困难了?

VOL.1ChatGPT能力显著增强了吗?
从今天开始,ChatGPT将使用刚刚发布的GPT-4 Turbo模型。这个模型支持的上下文token从8k提升到128k,相当于一本标准大小的300页纸质书所包含的文本量;奥特曼也表示,新模型在处理长文本情境下的准确度也有所提高。
我们用一个自己部署的开源客户端,调用了GPT-4 Turbo模型,来整理一篇飞书录音转文字的速记,目标是修改错别字及将口语变得更书面一些。这是娱乐资本论内部非常常用的一个prompt,但之前受限于生成效果及token长度,必须将一篇完整的文本对话提前拆分为很多段,每段最开始是1200字,后来可以扩展到2000字(使用Word字数统计)。
用来测试的速记原文有7863字,GPT-4 Turbo能支持完整输入整篇速记而不报错。不过,在输出时它大概停在了5200字左右,后面的没有继续生成。

速记原文

GPT-4 Turbo API调用的速记整理结果
换用ChatGPT,我们把速记全文贴进去,7000多字的文本也没有让它抱怨“太长”,开始在后台吭哧吭哧地整理了。

在主prompt之后暂停,并贴入全文
但是,ChatGPT出现了更明显的“忘词”情况,仅仅不到500字以后,它就忘记了prompt中“逐字处理速记”的要求,开始概括内容并大量丢掉段落。
究其原因,这可能是因为ChatGPT还有不可跳过的预设prompt,而且官方一直在更积极地弥补漏洞。而在仅使用API的情况下,它会忠实地执行你给它的prompt内容,而不是添油加醋。
因此,有条件的用户还是应该自行架设终端,调用GPT-4 Turbo的API接口,来确保生成结果的一致性。
我们的测试表明,在调用API逐字整理文本时,GPT-4 Turbo可用的文本长度大约是5000汉字;如果只是想要摘要,或就文档内容问答等简单任务,直接用ChatGPT就可以。
接下来,如果你只愿意用ChatGPT的官方界面,现在也有更好的体验了。因为这个界面当中,浏览网络、数据分析、文生图等都可以交叉调用,而不是像以前那样分开在不同的模式里使用。
理论上,这可以大大增加ChatGPT的可玩性,比如很多人期待的图生图功能,有的玩法很成功:
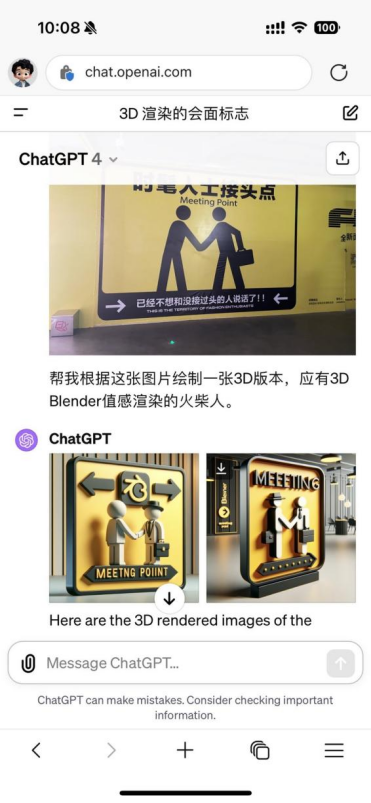
但也不是每次尝试都让人满意。比如,我安排的一个任务是,看他能不能识别一张新闻照片,并更改照片的画风。这个任务需要同时调用原本分开的识图、搜索和生图能力。
我们发现ChatGPT经过这次更新之后,多模态或联网功能有时会输出英文结果,即使用中文提问。好在这不算是什么大问题,浏览器自带翻译的质量也不差。
问题在于,识图的时候,ChatGPT不能一同联网,也没有以图搜图去寻找准确答案。
在联网的时候,ChatGPT运用了上一步生成的图片描述文字,因此只能不结合图像来猜测(当然他还是猜对了)。
以上的两个任务——速记整理和图生图——是非常简单的演示,对于文娱和媒体从业者的日常使用来说,还是我们老生常谈的一句话:你以前就用得上的能力,现在变得更好了;但以前就没实现的功能,现在也还是没有实现。
VOL.2“赶上或超越GPT”是不是更难了?
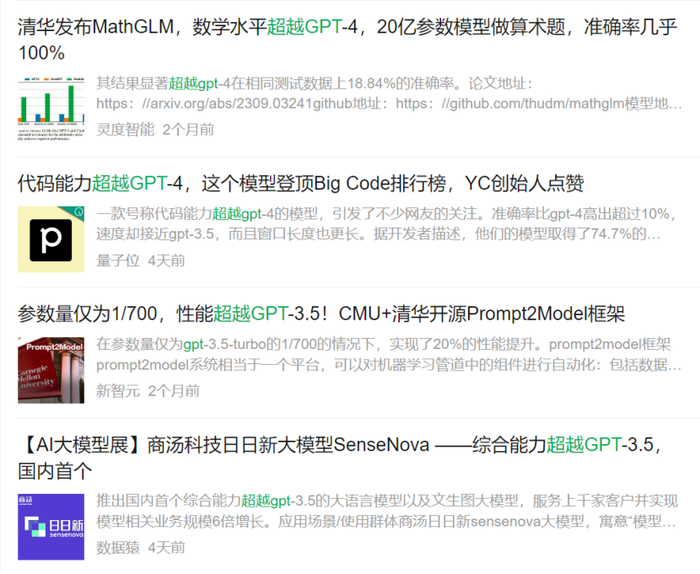
这是过去大半年来我们经常能在各处看到的景象。
目前已经通过国家备案的近20款大模型都有过类似的表述,说通过C-Eval、mmLU和AGIEval等测试集,它们在性能的某个角度或全局,都超越了GPT-3.5甚至GPT-4。
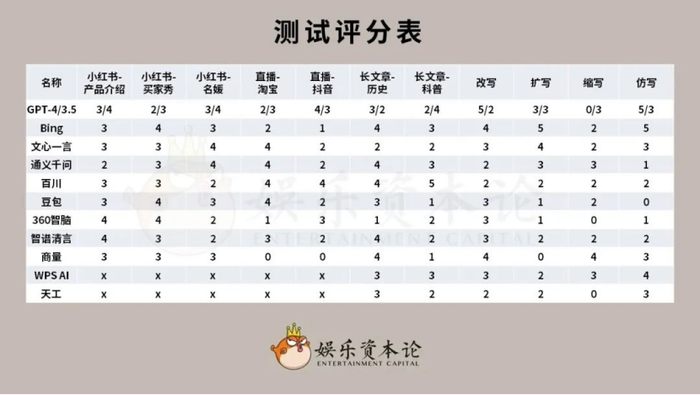
但是,用户实际上手使用的体验却是另一回事。根据娱乐资本论·视智未来9月份进行的第二次国产大模型实用场景测评,GPT-4在绝大多数问题上都会比国产友商们高1-2分(问题满分5分),假如其联网能力正常工作,恐怕分数还会更高。
此后,ChatGPT又推出多模态能力的重大升级。跟这个版本的ChatGPT相比,国产模型们的差距被拉得更大了。今天开发者大会后更新的ChatGPT,在性能的多数方面跟上次升级时一致。但如同上文所说,支持“300页图书”的长输入,将让它进一步挤占以此为卖点的大模型的生存空间,比如Claude、百川、月之暗面、零一万物等。
即使是外行人也能根据其他行业的经验猜出原因。比如,现在的数据集就那几个,“跑分”后再“优化”一下完全在情理之中。
尽管深度学习一向被视为“黑盒”乃至“盲盒”,但是在现在的大模型训练中,有针对性地调整参数,实现开发过程的可解释性,已经比一年前简单得多,这一定程度上归功于算力进步后“大力出奇迹”的贡献。
本周发布第一个模型成果的李开复团队“零一万物”,其技术合伙人黄文灏(履历有微软亚研和北京智源)就说道:
“当我们建立了自己的评测指标后,按照评测指标去优化模型的训练过程,团队内部就会对模型有很强的自信,知道做的所有工作都是在优化模型的能力。最后再去benchmark(测试数据集)上评测训练完的模型,会发现模型指标还是很不错的。这个算是个副产物吧,情理之中也意料之内。”
他认为,“大模型是极致的系统科学,基础做好了之后,模型在scale up(提升参数量)的过程中会无比‘丝滑’。”
由此可见,在当今“大炼模型”的浪潮中,这件事已经一定程度从科学乃至“玄学”领域,简化到了一个工程问题。正如猴子无限的尹伯昊对河豚君说过的:“算法很难有壁垒,但是工程能力是有壁垒的。”当时他形容的是大模型私有化这种中间层的竞争,但现在在基底的模型层,也出现了同样的倾向。
然而,各大模型的“基础”部分依然存在参差不齐的差距,这部分也更少有规律可循。微软之前一篇论文声称,ChatGPT的参数量仅有区区200亿(20B),当时可是引起了行业巨震——文心大模型参数2600亿,通义M6宣称参数规模10万亿,什么微软谷歌统统没法比。不过,微软此后又撤回了这部分数据。
读者们应该还记得ChatGPT突然“涌现”时给人带来的震撼。我们可以提供一个比较简单粗暴的判断方法:
如果某个大模型的升级版本,在实际使用中没有让你产生“惊艳”的,跟以前完全不一样了的感觉,它就还没有达到自己宣称的“超越GPT-x”的说法。
在本次开发者大会上,ChatGPT引入了很多人期待的Agent(代理)功能,被直白地称为“GPT们”。官方定义是,这是自定义版本的ChatGPT,融合了用户指定的初始prompt、额外的知识,以及执行特殊任务的能力(应该是API)。
此前,ChatGPT允许用户自定义两段话来优化输出结果,即“向GPT介绍你自己”和“你期待GPT怎么回答你”。这与创建“GPT”所需的材料非常相似,但这个设置会无条件应用于每一段对话,且效果也没有太显著。
新的“GPT”创建能力没有马上推出,而是要等到11月底。OpenAI方面放出了一些官方预置的“GPT”,我们尝试了其中一个“GenZ 4 meme”,它的长项是用拽拽的语气回答你对于欧美年轻人流行文化的疑问。

马斯克说X(Twitter)的大模型“Grok”默认回复语气就是有点儿不正经的那种,从“GPTs”的演示看,这可能只需要定义一个“GPT”就可以重现。
不过,现在有一个Bug是切换到“GPT”情景模式时,输入框不起作用,因此无法自己输入问题,不能上传图片,也无法追问。我们只能用它的默认问题,然后再点击“修改提问”来放入自己的prompt来变相使用。
跟国产大模型的“助理”、“分身”、“数字员工”等比起来,那些都只是一句预定义的prompt而已,你自己输入同一句话,效果是一样的。很显然“GPT”更为复杂,它需要增加在每次提问时都生效的用户prompt,还会加入预置的知识内容(虽然字数很少,但这相当于一个小型的私有化训练)。
我们认为,如果国产大模型想通过专门的能力定向优化,在某些任务上实现局部“超越GPT”的结果,这些定向优化的步骤,必须比只有一句prompt要更有诚意才行。要不然,以后每个ChatGPT的消费者都可以自己实现“专属模型”的效果了。
VOL.3如果OpenAI是“苹果”,国内友商会是“安卓”吗?
“科技春晚”这个称呼,最早被国内媒体用在形容苹果的发布会上,因为那时的苹果总是能给人们各种各样的惊喜,其它手机、电脑和手表厂商难以望其项背。
在很多次发布会带来的惊喜当中,苹果产品不知不觉地从一般人只能仰望,但是买不起的“高岭之花”,变成了更下沉、更大众的技术工具。更多人形成了无脑换新机的习惯,称为交“苹果税”。
最近这几年的苹果发布会,关注度远远比以前下降了,也和“春晚”本晚一样逐渐少人关注。这有多方面的原因:
·首先,苹果产品的创新虽然还有,但是相比以前,肯定是乏力了很多。
·然后,苹果现在的产品发布节奏也跟以前不同,有一些产品只发个新闻稿就上架了,没有挤在一年一两次集中发布。
·最后,各种国内竞品的竞争力逐渐赶上,苹果的独特性不再成为一种“刚需”和苦苦追求的梦想。
OpenAI被业界称为实现了AIGC的“iPhone时刻”,而这家公司本身,也一直将自己在行业中的地位与苹果相提并论,它也希望拥有扭转乾坤的“现实扭曲力场”。
从这一年来ChatGPT给用户和开发者的感受来看,它确实保持着跟国内外竞品的断层优势,而且尚未被开源阵营赶上。因此,可能也是时候把“科技春晚”的桂冠从苹果发布会的头上摘下来,戴到OpenAI发布会的头上了。
如果我们畅想未来,希望今后国产大模型围猎OpenAI,也像国产手机对阵苹果一样,至少在性价比、多样性、可用性等方面局部地胜出,具备一定的竞争力;如果我们希望未来OpenAI的发布会,也像现在的苹果发布会一样,不再让追赶者有那么强烈的无力感,那应该怎么做呢?
·首先,OpenAI虽然有强大的创新能力,但从历史规律看,它不可能永远保持领先。它可能会犯错,或者失去原先一样的增长速度。
·然后,OpenAI的未来产品发布也可能没有规律,有的计划中的发布可能拖延。
·最后,国内竞品和开源体系有可能在OpenAI发展放缓的时候,缩小与其之间的差距,甚至通过意外的“涌现”创造惊喜。
只要真正的创新一直在发生,我们相信大模型产品的成本终究会下降,也和苹果硬件一样,变成更下沉、更大众的技术工具。而在那样的未来当中,一定少不了中国厂家的身影。
最后,让我们用ChatGPT自己给本文画的题图,来作为这篇文章的结尾。

评论