
文|唐辰同学
OpenAI最新发布的文生视频大模型Sora,再一次验证ChatGPT路线的成功:数据精确处理后大规模预训练带来的智能涌现。从官方演示视频看,Sora能够根据文本提示创建详细的视频,扩展现有视频中的叙述以及从静态图像生成场景,最长能生成60秒视频。
一时间,Sora成为OpenAI的新爆款,被全球追捧。马斯克感叹“人类愿赌服输”,360集团创始人、董事长兼CEO周鸿祎预言“AGI实现将从10年缩短到1年”。
但“XX已死,AI一夜变天”、“现实不存在了”、“这个行业要完蛋了”等两极分化的观点也瞬间充斥网络。观察各种讨论和信息后,整理出10个信息点,作为学习资料分享给大家。
1、为什么叫Sora?有什么含义?
Sora这个名字取自日语单词,意为“天空”,引申含义还有“自由”。在Sora官网页面,无数只纸飞机在自由飞翔,行动自主,最后汇集成一片天空的背景色。
此外,Sora这个词在在韩语中表示海螺壳,在芬兰语中表示砂砾,很容易让人联想到《海底两万里》的鹦鹉螺号和科幻片《沙丘》。
硅基立场提到,Sora在日语里有时候会用作动词,意思是“用心记,而不用看任何写下来的材料”,变化出来的词比如“Soranjiru”, そらんじる 的意思就是“remember by heart”,这不正是Sora的能力?
官方说法是这样,研究团队成员蒂姆·布鲁克斯和比尔·皮布尔斯介绍,选择这个名字,是因为它能“唤起无限的创造潜力”。
2、现实不存在了?Sora到底有多炸裂!
OpenAI官方网站贴出了Sora创作的东京街头视频。提示词是:
“美丽的、白雪皑皑的东京市,镜头穿过熙熙攘攘的城市街道,跟随几名行人享受美妙的雪天,有人在路边小摊购物。绚丽的樱花与雪花一起在风中飞舞。”

Sora制作的视频
另一个视频根据如下提示词产生:
“几只巨大的、毛茸茸的猛犸象,踩着白雪皑皑的地面走近,风吹动它们身上的长长毛发,远处是白雪覆盖的高大树木和雄伟山脉,午后的光线营造出温暖的光芒。”

Sora制作的猛犸象视频/OpenAI
由此可以看出,Sora让“一句话(prompt)生成视频”成为可能。这种能力的震撼之处在于, Sora在模拟物理世界时,能够更准确地反映出现实世界的复杂性和多样性。有了提示词,Sora就“知道”如何用镜头语言讲故事。
出门问问创始人兼CEO李志飞认为,“视频”作为物理世界的映像,是世界模型渲染出来的结果。相比语言数据,通过视频大数据学习到的模型是“模型的模型” ,同时学到了很多物理世界规律,让模型更加逼近模拟物理世界。
文本与视频的区别在于,前者是理解人类的逻辑思维,后者在于理解物理世界。所以,视频生成模型 Sora 如果能很好跟文本模型 LLM 融合,那它真有望成为世界的通用模拟器。如果有一天,这样的系统自己通过模拟驾车场景,学会了在城市复杂的交通环境下开车,人类也不会奇怪。
不少从业者惊呼“现实不存在了”即是源于此。
3、Sora为何被称为世界模拟器?
“文生视频大模型”并不是一条全新的赛道。在Sora发布之前,Google、Stability AI等头部大厂都拥有自己的文生视频大模型。甚至诞生了垂直内容创作大模型的独角兽,例如视频生成大模型Gen-2的开发商Runway,在2023年6月底完成由Google、Nvidia等参与的C轮融资后,估值超过15亿美元。
但和ChatGPT的故事如出一辙,Sora登场就碾压对手。在此之前,AI视频生成领域的明星产品Runway和Pika,只能做3或4秒长的模糊视频,角色形象也很扭曲,还得用户输入图片。
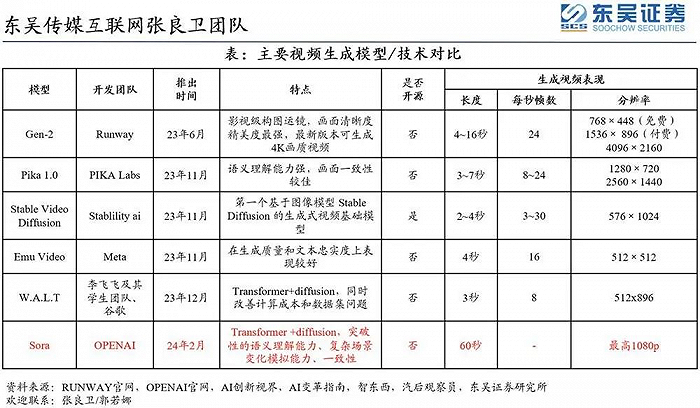
主要视频生成模型/技术对比(来源:东吴证券)
OpenAI并未单纯将Sora视为视频模型,而是作为“世界模拟器”。它能像人一样,理解坦克是有巨大冲击力的,坦克能撞毁汽车,而不会出现“汽车撞毁坦克”这样的情况,这就是“世界模型”的强大之处。
Sora拥有三大关键特点:60秒超长长度、单视频多角度镜头以及世界模型。其中,“世界模型”是指通过对真实物理世界的模拟,让计算机可以像人类一样全面、准确地“认知”世界。
Sora背后拥有两大技术革新:时空补丁(Spacetime Patch)技术和扩散型Transformer(Diffusion Transformer,简称DiT)架构。OpenAI发现训练计算量越大,样本质量就会越高,特别是经过大规模训练后,Sora展现出模拟现实世界某些属性的“涌现”能力。
虽然Sora在物理规则模拟方面仍然存在不足。例如,一段展示老奶奶吹蜡烛的视频中,蜡烛并未随风熄灭;另一段视频中,玻璃杯从空中坠落却未破裂,水却已流出。
但Sora的作品达到了惊人的高清照片级真实感,“运镜”手法更令人难忘——围绕同一主体实现远景、中景、近景、特写等不同镜头的切换。这已经表明,通过大量数据的分析,机器能够推断出一些物理世界的规则,这无疑是向现实世界模拟迈出的重要一步。
值得一提的是,Sora所展现出来的“精准的物理世界还原能力”,也并不是OpenAI独自探索的AI领域。“世界模型”最早是由图灵奖得主、Meta首席科学家杨立昆(Yann LeCun)2023年6月提出。2023年12月,Runway宣布建造“通用世界模型”,用生成式AI模拟整个世界。马斯克也称,特斯拉掌握“精准还原现实世界物理规律的虚拟世界生成能力”快一年了。
4、Sora为何能实现如此震撼的效果?
Sora模型基于Transformer架构,建立在DALL·E 3和GPT模型之上,使用文本到视频的合成技术,按文本提示生成视频。这种技术将自然语言转换为视觉表示形式——图像或视频。


OpenAI在官网展示Sora的生成逻辑
深度神经网络依然是Sora的基础,它是一个带有Transformer骨架的扩散(Diffusion)模型,AI从数据中学习并执行复杂的任务。Sora就是从“学习”的大型视频数据集里学会了各种风格、主题和流派。
Transformer模型本质是一个编码器-解码器,输入原始语言,生成目标语言。扩散模型的原理是先给数据添加高斯噪声,再反向去除,从中恢复数据本貌。简单粗暴地理解Sora的原理,就是翻译器+搜索引擎+概率制作(内容)。
首先,拿到提示词后,Sora先分析文本,提取关键字,比如主题、动作、地点、时间和情绪,再从它的数据集里搜索与关键字匹配的、最合适的视频。
其次,Sora将数据集里合适的视频混合在一起,重新创建一个符合要求的视频。在“创造”的过程中,它要“知道”场景中有哪些对象和角色,它们的外形,它们如何运动,对象如何交互,以及受到环境影响后如何表现。
根据用户的喜好,Sora会修改视频的风格。假如用户想要一个35毫米胶片样式的视频,Sora会调整效果,更改图像的亮度、色彩和摄像机角度。这一点和Midjourney等“文生图”应用类似。
Sora可以生成分辨率1920x1080的视频,也可以基于静止图片创建视频,使用新素材扩展现有素材。比如用户给它一张森林图片,它可以帮你加上鸟、兽、人。给它一张汽车行驶图,它能加上道路、交通灯、沿途建筑物和风景。

Sora将两段视频结合后产生的奇幻景象/OpenAI
5、怎么理解Scaling Law(缩放定律)?
Sora和ChatGPT类似,是OpenAI的Scaling Law(缩放定律)的又一次成功:只要模型足够“大”,根据特定算法,就会产生智能“涌现”的能力。大模型的Scaling Law是OpenAI在2020年提出的概念,不仅适用于语言模型,还适用于其他模态以及跨模态的任务。
根据相关资料可以得到一个简单介绍:Scaling Laws随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高。并且为了获得最佳性能,所有三个因素必须同时放大。当不受其他两个因素的制约时,模型性能与每个单独的因素都有幂律关系。
GPT-4报告中,明确指出:
The results on the 3rd easiest bucket are shown in Figure 2, showing that the resulting predictions were very accurate for this subset of HumanEval problems where we can accurately estimate log(pass_rate) for several smaller models.
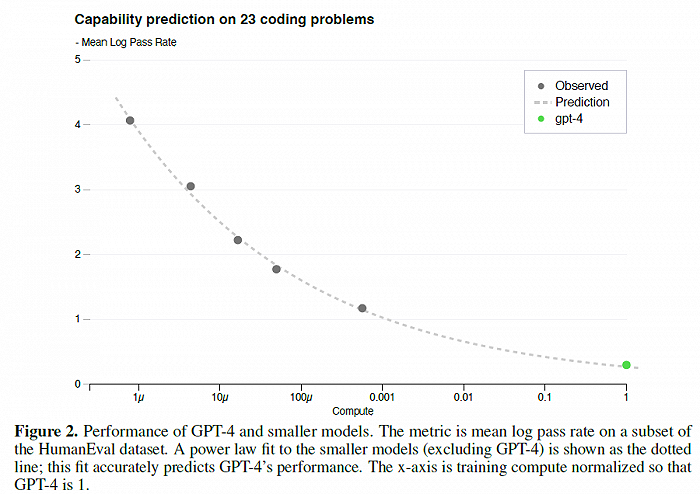
在第3简单的23个代码问题上的性能预测
简单翻译一下,GPT-4在这23个问题上的性能预测,可以通过比GPT-4小1000倍的模型预测得来。也就是说GPT-4还没开始训练,它在这23个问题上的性能就已经知道了。
可以跳过上述学术描述,直接理解为,Scaling Laws对于大模型的训练很重要!硅基立场认为,Scaling Laws正在快速变成一种路线,充满OpenAI领导者Altman的意志,也正变成这家公司的核心战略。
6、Sora团队有何“天才”之处?
根据OpenAI官网介绍,Sora核心团队共有15人,而从公开资料显示的毕业和入职时间来看,这支团队的成立时间尚未超过1年。

除了由伯克利应届博士生带队,有多名LeCun学生参与。其中还有包括北大校友在内的3位华人研究员,以及20岁就加入OpenAI的天才工程师。
7、重塑AGI的Sora如何影响世界?
360公司董事长周鸿祎的预言,即Sora的出现可能将实现通用人工智能(AGI)的时间从十年缩短至仅一年。许多人认为,Sora首先将对影视行业造成冲击。将来,影视剧制作的门槛会将会大大降低,只要心里有故事,就可借助强大的AI工具进行创作。
AI电影《山海奇境》的制作人陈坤提到,Sora通过展示其视频能力,旨在收集用户反馈,进一步探索和预测人们期望生成的视频内容。这一过程类似于大规模模型训练,全球用户的互动不断丰富和优化了其世界模型,推动AI在模拟现实世界方面变得更加精准和智能。
不同行业的巨头也感受到Sora的“威能”:游戏公司育碧视其为一次巨大的飞跃;华大集团CEO尹烨将其比作开启了AI发展的“牛顿时代”;而Meta的首席人工智能科学家、图灵奖得主LeCun则批评Sora无法真正理解物理世界。
8、Sora制造焦虑么?
Sora值得更多的赞誉,但过度神话大可不必。贩卖焦虑的不是Sora,喊出“现实不存在”,就两类人,一类是AI门徒,一类是正在卖课割韭菜。应该向前者致敬,而后者正如这张流传甚广的照片,典型如李一舟,正卖付费课程从你口袋掏钱。
对于普通人,人工智能是一套辅助工具。想靠着买课听来的信息赚钱,只会是竹篮打水一场空。真正带来压迫感的,或许是Sora不可思议的进化速度。例如,Gen-2是2023年6月发布的产品,距离Sora的发布不过8个月。
支撑OpenAI以如此速度迭代的是“疯狂烧钱”,也是“大力出奇迹”的驱动力。知乎上,一位叫做“像素炼金师”的创业者坦承了他在目睹Sora发布后的心路历程:“我有些害怕科技巨头的产品像隆隆火车一样驶过,而我做的东西如同路边的野草一样,在这个技术进步就像跑马灯一样的时代里,留不下一丝痕迹。”
9、OpenAI使了多大力?
Stability AI CEO Emad Mostaque曾称,人工智能作为基础设施所需的投资总额可能为1万亿美元,这会是人类有史以来最大的泡沫。
OpenAI训练GPT-4,用了大约25000块A100 GPU 。而训练GPT-5,还需要5万张H100,目前这张GPU的售价在2.5万至3万美元,还要排队。
为支撑OpenAI技术发展所需要的算力,“奥特曼”宣布启动“造芯”计划,筹集多达5万亿至7万亿美元的资金,生产芯片。这个募资规模,可以买下包括英伟达、台积电、英特尔、三星在内的十八家芯片巨头,以及社交巨头Meta,还剩3000亿美元。按照英伟达CEO黄仁勋的说法,7万亿美元能买下全球所有的GPU。
10、Sora面临的挑战有哪些?
首先是成本,Sora很强,但也更贵。小冰CEO李笛曾算过一笔账,如果把全中国所有媒体的撰稿工作全部由大模型来完成,颠覆掉了一个市场、端掉了很多撰稿人的饭碗,AI公司获得的也不过是200万左右的市场规模。大力出奇迹,但不是每家公司都有OpenAI的实力。
还有一个老生常谈的问题,Sora生成内容的版权问题也一直在被不断规范。比如,美国联邦贸易委员会(FTC)2月15日提出了禁止使用AI工具冒充个人的规则。FTC表示,它正在提议修改一项已经禁止冒充企业或政府机构的规则,将保护范围扩大到所有个人。
OpenAI内部也在进行模型伦理方面的对抗性测试,包括拒绝处理错误信息、仇恨内容、偏见内容和色情暴力等。
如今,山姆.阿尔特曼就像百年前的奥本海默,正在搭建影响未来的基础设施,并且还在不断同竞争对手拉开差距。
相较于ChatGPT的人声鼎沸,这一次,中国企业家和创投圈的公开“对比”,明显沉寂很多。但赛道外,妄自菲薄、腹诽以及嘲讽的声量却不绝于耳。此种情形,个人十分认同硅基立场的观点:
我们不缺同样带来极佳体验的AI模型和产品,也不缺技术社区影响力极佳的个体和作品,但却没有在我们自己的讨论里形成该有的关注,也许所有人该放开一些包袱了。我们对自己严苛到妄自菲薄的事实也在起着反作用。
以对原创技术的理解和定义为例,OpenAI不是Transformer模型发明者,Stable Diffusion不是Diffusion模型发明者,Mistral不是MoE发明者。如果对标,它们本质都可以理解是一个个ASML,
所以“我们为什么没有诞生OpenAI”是不是并不等于“我们为什么没从头发明某某技术”?是不是哪怕一家像ASML这样的“只做沙子的搬运工”的公司,今天诞生在中国也躲不过先被骂套壳的命运?有时候,问题提错了可能一切就都错了。
综合内容:
智东西,《Sora爆火48小时,大佬们怎么看?》
投中网,《“今天,所有VC的会上都在谈Sora”》
硅基立场,《Sora带来的四点启发》
南风窗,《东京街头视频流出,硅谷巨头不淡定了》
飞哥说AI,《为什么说 Sora 是世界的模拟器?》
评论