
文|硅谷101
Sora,OpenAI的人工智能AI生成式视频大模型,在2024年2月15日一经发布,就引发了全球关注,硅谷AI视频论文作者(非Sora)这样评价:相当好,这是毋庸置疑的No.1。

Sora好在哪里?生成式AI视频的发展挑战在哪里?OpenAI的视频模型一定是正确的路线吗?所谓的“世界模型”达成共识了吗?这期视频,我们通过与硅谷一线AI从业人员的采访,深度聊聊生成式AI视频大模型的不同派系发展史,大家的争议和未来路线。
AI生成视频这个题我们其实去年就想做了,因为当时跟很多人聊天,包括跟VC投资人聊的时候,发现其实大家对AI视频模型和ChatGPT这种大语言模型的区别并不是很清楚。但是为啥没做呢,因为在去年年底,市场中做得最好的也就是runway这家公司旗下的Gen1和Gen2两种视频生成视频以及文字生成视频的功能,但我们生成出来的效果... 有点一言难尽。
比如说,我们用runway生成的一个视频,prompt提示词是”super mario walking in a desert”(超级马里奥漫步于沙漠中),结果出来的视频是这样的:

怎么看怎么像马里奥跳跃在月球上。无论是重力还是摩擦力,物理学在这段视频里好像突然不复存在。
然后我们尝试了另外一个提示词,“A group of people walking down a street at night with umbrellas on the windows of stores.”(雨夜的大街上,一群人走在商铺窗户檐的伞下)这段提示词也是一个投资人Garrio Harrison尝试过的,结果出来的视频,是这样的:

你看这空中漂浮的雨伞,是不是很诡异... 但这已经是去年代表着最领先技术的runway了。之后华人创始人Demi Guo创立的Pika Labs火了一阵,被认为比runway效果稍好一些,但依然受制于3-4秒的长度显示,并且生成的视频仍然存在视频理解逻辑、手部构图等缺陷问题。
所以,在OpenAI发布Sora模型之前,生成式AI视频模型并没有像ChatGPT、Midjourney这样的聊天和文生图应用一样引发全球关注,很大原因就是因为生成视频的技术难度非常高,视频是二维空间+时间,从静态到动态,从平面到不同时间片段下的平面显示出的立体效果,不但需要强大的算法和算力,还需要解决一致性、连贯性、物理合理性、逻辑合理性等等一系列的复杂问题。

所以,生成式视频大模型这个选题,一直都在我们硅谷101的选题单上,但一直拖着没做,想等生成式AI视频模型有一个重大突破的时候,我们再来做这个选题,结果没想到,这么快,这个时刻,就来了。
01 生成式AI视频的ChatGPT时刻?
Sora的展示,毫无疑问是吊打此前的runway和pika labs的。
首先,最大的突破之一,很直观的就是:生成视频长度大大的延长了。之前,runway和pika都只能生成出3-4秒的视频,太短了,所以之前能出圈的AI视频作品,就只有一些快节奏的电影预告片,因为其它需要长一些素材的用途根本无法被满足。

而在runway和pika上,如果需要更长的视频,你就需要自己不断提示叠加视频时长,但我们视频后期剪辑师Jacob就发现,这会出现一个大问题。
Jacob,硅谷101视频后期剪辑师:
痛点就是你在不断往后延长的时候,它后面的视频会出现变形,就会导致前后视频画面的不一致,那这段素材就用不了了。
而Sora最新展示的论文和demo中表示,可以根据提示词,直接生成1分钟左右的视频场景。与此同时,Sora会兼顾视频中人物场景的变换以及主题的一致性。这让我们的剪辑师看了之后,也直呼兴奋。

Jacob,硅谷101视频后期剪辑师:(Sora)其中有一个视频是一个女孩走在东京的街头... 对我来说,这个是很厉害的。所以,就算在视频动态的运动情况下,随着空间的移动和旋转,Sora视频中出现的人物和物体会保持场景一致性的移动。
第三,Sora可以接受视频,图像或提示词作为输入,模型会根据用户的输入来生成视频,比如,公布出demo中的一朵爆开的云。这意味着,Sora模型可以基于静态图像来制作动画,做到在时间上向前或者向后来扩展视频。

第四,Sora可以读取不同的无论是宽屏还是垂直视频、进行采样,也可以根据同一个视频去输出不同尺寸的视频,并且保持风格稳定,比如说这个小海龟的样片。这其实对我们视频后期的帮助是非常大的,现在Youtube和B站等1920*1080p横屏视频,我们需要重新剪成垂直1080*1920的视频来适配抖音和Tiktok等短视频平台,但可以想象,之后也许就能通过Sora一键AI转换,这也是我很期待的功能。
第五,远距离相干性和时间连贯性更强了。此前,AI生成视频有个很大的困难,就是时间的连贯性,但Sora能很好的记住视频中的人和物体,即使被暂时挡住或移出画面,之后再出现的时候也能按照物理逻辑地让视频保持连贯性。比如说Sora公布的这个小狗的视频,当人们走过它,画面被完全挡住,再出现它的时候,它也能自然地继续运动,保持时间和物体的连贯。

第六,Sora模型已经可以简单地模拟世界状态的动作。比如说,画家在画布上留下新的笔触,这些笔触会随着时间的推移而持续存在,或者一个人吃汉堡的时候会留下汉堡上的咬痕。有比较乐观的解读认为,这意味着模型具备了一定的通识能力、能“理解”运动中的物理世界,也能够预测到画面的下一步会发生什么。

因此,以上这几点Sora模型带来的震撼更新,极大地提高了外界对生成式AI视频发展的期待和兴奋值,虽然Sora也会出现一些逻辑错误,比如说猫出现三只爪子,街景中有不符合常规的障碍物,人在跑步机上的方向反了等等,但显然,比起之前的生成视频,无轮是runway还是pika还是谷歌的videopoet,Sora都是绝对的领先者,而更重要的是,OpenAI似乎通过Sora想证明,堆算力堆参数的“大力出奇迹”方式也可以适用到生成式视频上来,并且通过扩散模型和大语言模型的整合,这样的模型新路线,来形成所谓的“世界模型”的基础,而这些观点,也在AI届引发了极大的争议和讨论。
接下来,我们就来试图回顾一下生成式AI大模型的技术发展之路,以及试图解析一下,Sora的模型是怎么运作的,它到底是不是所谓的“世界模型”?
02 扩散模型技术路线:Google Imagen,Runway,Pika Labs
AI生成视频的早期阶段,主要依赖于GAN(生成式对抗网络)和VAE(变分自编码器)这两种模型。但是,这两种方法生成的视频内容相对受限,相对的单一和静态,而且分辨率往往不太行,完全没办法进行商用。所以这两种模型我们就先不讲了哈。

之后,AI生成视频就演变成了两种技术路线,一种是专门用于视频领域的扩散模型,一种则是Transformer模型。我们先来说说扩散模型的路线,跑出来的公司就有Runway和Pika Labs等等。
03 什么是扩散模型?
扩散模型的英文是Diffusion Model。很多人不知道,如今最重要的开源模型Stable Diffusion的原始模型就是由Runway和慕尼黑大学团队一起发布的,而Stable Diffusion本身也是Runway核心产品—视频编辑器Gen-1和Gen-2背后的底层技术基础。

Gen-1模型在2023年2月发布,允许大家通过输入文本或图像,改变原视频的视觉风格,例如将手机拍摄的现实街景变成赛博世界。而在6月,runway发布Gen-2,更近一步能将用户输入的文本提示直接生成为视频。
扩散模型的原理,大家一听这个名字“扩散模型”,就能稍微get到:是通过逐步扩散来生成图像或视频。为了更好的给大家解释模型原理,我们邀请到了之前Meta Make-A-Video模型的论文作者之一、目前在亚马逊AGI团队从事视频生成模型的张宋扬博士来给我们做一个解释。
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
之所以最开始这篇论文之所以用扩散这个名字,是源于一个物理现象,就是说比如说我们把墨水滴到一杯水里面去,墨水它会散开,这个东西叫扩散。这个过程本身物理上是不可逆的,但是我们AI可以学习这么一个过程,把这个过程给逆过来。它类比到图片里面来说,就是一个图片,它是不断加噪声不断加噪声,然后它会变成一个类似于马赛克这样的一个效果。它是一个纯噪声的一张图片。然后我们学习怎么把这个噪点变成一张原始的图片。
我们训练这么样的一个模型,直接去一步完成的话,这个可能会很难,它分成了很多步,比如我分成1000步,比如说我加一点点噪声,它能够还原出去噪声后是什么样子,然后噪声加得比 较多的时候,我该怎么去用这个模型怎么去预测噪声?就是它分了很多步,然后逐渐地去把这噪声慢慢地去掉,它迭代式地把这个噪声慢慢给去掉。比如说原来是一个水跟墨已经完全混合在一起了,你想办法怎么去预测它,一步一步它如何再变回之前的那一滴墨水的样子。就是它是一个扩散的一个逆过程。
张宋扬博士解释得很形象,扩散模型的核心思想是通过不断地向原始噪声引入随机性,逐步生成逼真的图像或视频。在而这个过程分成了四步:
1)初始化:扩散模型开始于一个随机的噪声图像或视频帧作为初始输入。
2)扩散过程(也被称为前向过程forward process):扩散过程的目标是让图片变得不清晰,最后变成完全的噪声。
3)反向过程(reverse process,又被称为backward diffusion):这时候我们会引入“神经网络”,比如说基于卷积神经网络(CNN)的UNet结构,在每个时间步预测“要达到现在这一帧模糊的图像,所添加的噪声”,从而通过去除这种噪声来生成下一帧图像,以此来形成图像的逼真内容。
4)重复步骤:重复上述步骤直到达到所需的生成图像或视频的长度。

以上是video to video或者是picture to video的生成方式,也是runway Gen1的大概底层技术运行方式。如果是要达到输入提示词来达到text to video,那么就要多加几个步骤。
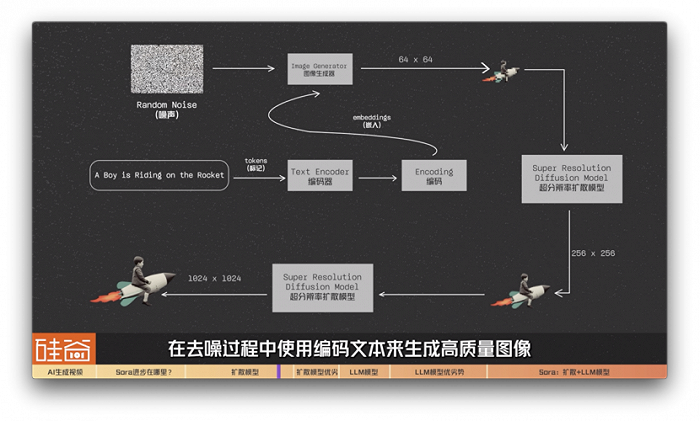
比如说我们拿谷歌在2022年中旬发布的Imagen模型来举例:我们的提示词是a boy is riding on the Rocket,骑着火箭的男孩。这段提示词会被转换为tokens(标记)并传递给编码器text encoder。谷歌 IMAGEN模型接着用T5-XXL LLM编码器将输入文本编码为嵌入(embeddings)。这些嵌入代表着我们的文本提示词,但是以机器可以理解的方式进行编码。
之后这些“嵌入文本”会被传递给一个图像生成器image generator,这个图像生成器会生成64x64分辨率的低分辨率图像。之后,IMAGEN模型利用超分辨率扩散模型,将图像从64x64升级到256x256,然后再加一层超分辨率扩散模型,最后生成与我们的文本提示紧密结合的 1024x1024 高质量图像。
简单总结来说,在这个过程中,扩散模型从随机噪声图像开始,在去噪过程中使用编码文本来生成高质量图像。
04 扩散模型优劣势
而生成视频为什么要比生成图片困难这么多?
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:它的原理实际上还是一样的,只不过唯一一个区别就是多了一个时间轴。就是刚刚我们说的图片,它是一个2D的,它是高度跟宽度。然后视频它多一个时间轴,它就是一个3D的,它就是高度、宽度还有一个时间。然后它在学习这个扩散的逆过程的过程当中,就是相当于以前是一个2D的逆过程,现在变成一个3D的逆过程,就是这么一个区别。

所以说图片上的存在的问题,比如说像这些生成的人脸它是不是真实啊?那我们如果图片存在这样的问题,我们视频也一样会存在这样的问题。对于视频来说,它有一些它有些独特的一些问题,就比如说刚才像你说的这个画面的主体是不是保持一致的?我觉得目前对于像风景这样的,其实效果都还可以,然后但是如果涉及到人的话,因为人的这些要求可能会更精细,所以说人的难度会更高,这是一个问题。然后还有一个目前的难点,我觉得也是大家都在努力的一个方向,就是怎么把视频变得更长。因为目前来说的话,只生成2秒、3秒、4秒这样的视频,其实远远满足不了现在的应用场景。

扩散模型比起之前的GAN等模型来说,有三个主要的优点:
第一,稳定性:训练过程通常更加稳定,不容易陷入模式崩溃或模式塌陷等问题。
第二,生成图像质量: 扩散模型可以生成高质量的图像或视频,尤其是在训练充分的情况下,生成结果通常比较逼真。
第三,无需特定架构: 扩散模型不依赖于特定的网络结构,兼容性好,很多不同类型的神经网络都可以拿来用。
然而,扩散模型也有两大主要缺点,包括:
首先,训练成本高:与一些其他生成模型相比,扩散模型的训练可能会比较昂贵,因为它需要在不同噪声程度的情况下学习去燥,需要训练的时间更久。
其次,生成花费的时间更多。因为生成时需要逐步去燥生成图像或视频,而不是一次性地生成整个样本。
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
就是我们其实现在无法生成长的视频一个很重要原因就是,我们的显存是有限的。生成一张图片可能占用一部分的显存,然后你如果生成16张图片,就可能差不多把这显存给占满了。当你需要生成更多张图片的时候,你就得想办法怎么去,既考虑之前已经生成的这些信息,然后再去预测后面该生成什么样的信息。它首先在模型上面就提了一个更高的要求,当然算力上面也是一个问题,就是获取过很多年之后,我们的显存会非常的大,可能我们也就不存在这样的问题了,也是有可能的,但是就目前来说,当下我们是需要一个更好的一个算法,但是如果有更好硬件可能这个问题就不存在。
所以,这注定了目前的视频扩散模型本身可能不是最好的算法,虽然runway和PikaLabs等代表公司一直在优化算法。
我们接下来,聊聊另外一个派别:基于Transformer架构的大语言模型生成视频技术路线。
05 大语言模型生成视频技术路线(VideoPoet)
最后,谷歌在2023年12月底发布了基于大语言模型的生成式AI视频模型VideoPoet,这在当时被视为生成视频领域中,扩散模型之外的另外一种解法和出路。它是这么个原理呢?
大语言模型如何生成视频?
大语言模型生成视频是通过理解视频内容的时间和空间关系来实现的。谷歌的VideoPoet是一个利用大语言模型来生成视频的例子。这个时候,让我们再次请出生成式AI科学家张宋扬博士,来给我们做一个生动的解释。
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
然后大语言模型这个东西,原理上完全不一样,它最一开始是用在文本上面,用在文本上面就是说我预测下一个单词是什么,就比如说“我爱说实话”,然后最后一个“我爱说实”,然后最后一个字是什么?你猜是什么字?然后可能你给的这些前面的字越多,你可能越容易猜到后面。但是如果你给的字比较少,你可能发挥空间会更多,它是这么样一个过程。

然后这个思路带到了视频当中,那就是我们可以学一个图片的词汇,或者说是视频的词汇。就是说我们可以把图片横着切,比如说横着切16刀,竖着切16刀,然后把每一个小方块、小格子当成一个词,然后把它输到这个大语言模型当中,让他们学习。比如说之前你已经有一个很好的一个大语言模型了,然后你去学习怎么大语言模型的这些词跟这些文本的词或者视频的词进行一个交互,它们之间的进行一个关联,是一个什么样的关联?你去学一些这个东西,然后这样的话,我们就可以利用这些大语言模型,让它可以去做一些视频的任务,或者是文本的一些任务。
简单来说,基于大语言模型的Videopoet是这样运作的:
1)输入和理解:首先Videopoet接收文本,声音,图片,深度图,光流图,或者有待编辑的视频作为输入。
2)视频和声音的编码:因为文本天然就是离散的形式,大语言模型自然而然就要求输入和输出必须是离散的特征。然而视频和声音是连续量,为了让大语言模型也能让图片,视频或者声音作为输入和输出,这里Videopoet将视频和声音编码成离散的token。在深度学习中,token是一个非常重要的概念, 它是指一组符号或标识符,用于表示一组数据或信息中的一个特定元素。在Videopoet的例子中,通俗一点可以理解成视频的单词和声音的单词。
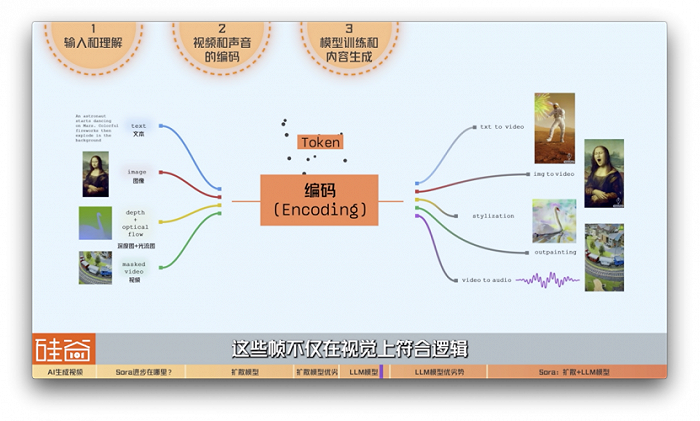
3)模型训练和内容生成:有了这些Token词汇,就可以根据用户给的输入,像学习文本token那样,训练一个Transformer去学习逐个预测视频的token,模型就会开始生成内容。对于视频生成,这意味着模型需要创建连贯的帧序列,这些帧不仅在视觉上符合逻辑,还要在时间上保持连续性。
4)优化和微调:生成的视频可能需要进一步的优化和微调,以确保质量和连贯性。这可能包括调整颜色、光照和帧之间的过渡等。VideoPoet利用深度学习技术来优化生成的视频,确保它们既符合文本描述,又在视觉上吸引人。
5)输出:最后,生成的视频会被输出,供最终用户观看。

但是,大语言模型生成视频的路线,也是优点和缺点并存的。
06 大语言模型生成视频优劣势
先来说说优点:
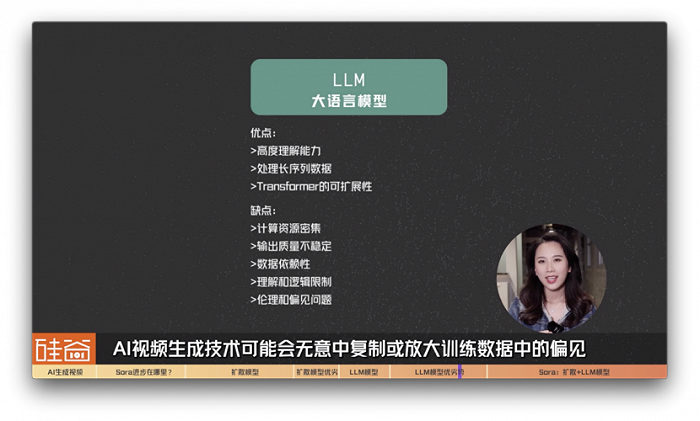
1)高度理解能力: 基于Transformer架构的大语言模型能够处理和理解大量的数据,包括复杂的文本和图像信息。这使得模型能具有跨模态的理解和生成能力,能够很好学到文本和图片视频不同模态之间关联的能力。这使得它们在将文本描述转换成视频内容时,能够生成更准确和相关的输出。
2)处理长序列数据: 由于自注意力机制,Transformer模型特别擅长处理长序列数据,这对于视频生成尤其重要,因为视频本质上是长序列的视觉表示。
3)Transformer的可扩展性:通常来说模型越大,拟合的能力就越强。但当模型大到一定程度时,卷积神经网络性能受模型增大带来的增益会放缓甚至停止,而Transformer仍能持续增长。Transformer在大语言模型已经证明了这一点,如今在图片视频生成这一领域也逐渐崭露头角。
再来说说缺点:
1)资源密集型:用大语言模型生成视频,特别是高质量视频,需要大量的计算资源,因为用大语言模型的路线是将视频编码成token,往往会比一句话甚至一段话的词汇量要大的多,同时,如果一个一个的去预测,会让时间的开销非常大。也就是说,这可能使得Transformer模型的训练和推理过程变得昂贵和时间消耗大。
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
有一个问题我觉得挺本质的,就是transformer它不够快,这个是很本质的一个问题,因为transformer它一个小方块一个小方块地预测,扩散模型直接一张图就出来了,所以transformer肯定会比较慢的。
陈茜,硅谷101视频主理人:
太慢了有一个具象的一个数据吗?就是能慢多少?
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
就比如说我直接出一张图,diffusion比如出一张图就是1,它也需要一些迭代过程。然后比如说我用四步,它就是四步去生成出来,咱就是4。现在目前做得好的话,四步我看有做的效果还是不错的。然后但是你要是用transformer的话,比如说你画16*16的方格,那就是16*16,那就等于256了,就是那个速度。
4是相当于我做去噪迭代了四次。然后transformer的话,它是相当于我去预测一张图片,比如说是16*16的话,我就预测256个词。他们的量纲肯定不一样,但是他们的复杂度你是可以看出来的。就是diffusion模型,它的复杂度是一个常数集。但是transformer的那个复杂度,它实际上是一个宽度x高度,复杂度会不一样。所以说从复杂度角度来说,肯定是扩散模型会更优一些。然后具体我觉得这东西可能你如果是图片越大的话,分辨率越高的话,transformer的问题可能会越大。
Transformer模型的另外一些问题还包括:
2)质量波动:尽管Transformer模型能够生成创造性的视频内容,但输出的质量可能不稳定,特别是对于复杂的或未充分训练的模型。
3)数据依赖性:Transformer模型的性能在很大程度上取决于训练数据的质量和多样性。如果训练数据有限或有偏差,生成的视频可能无法准确反映输入的意图或在多样性上存在限制。
4)理解和逻辑限制:虽然Transformer模型在理解文本和图像内容方面取得了进步,但它们可能仍然难以完全把握复杂的人类情感、幽默或细微的社会文化信号,这可能会影响生成视频的相关性和吸引力。
5)伦理和偏见问题:自动视频生成技术可能会无意中复制或放大训练数据中的偏见,导致伦理问题。
不过说到第五点,我突然想起来最近的这么一个新闻,说谷歌的多模态大模型Gemini中,无论你输入什么人,出来的都是有色人种,包括美国开国元勋,黑人女性版本的教皇,维京人也是有色人种,生成的Elon Musk也是黑人。

这背后的原因可能是谷歌为了更正Transformer架构中的偏见,给加入了AI道德和安全方面的调整指令,结果调过头了,出了这个大乌龙。不过这个事情发生在OpenAI发布了Sora之后,确实又让谷歌被群嘲了一番。
不过,业内人士也指出,以上的这五点问题也不是transformer架构所独有的,目前何生成模型都可能存在这些问题,只是不同模型在不同方向的优劣势稍有不同。

所以,到这里总结一下,扩散模型和Transformer模型生成视频都有不甚令人满意的地方,那么,身为技术最为前沿的公司OpenAI他们是怎么做的呢?诶,也许你猜到了,这两模型各有千秋,我把它们结合在一起,会不会1+1>2呢?于是,Sora,也就是扩散模型和Transformer模型的结合。
07 Sora的扩散+大语言模型:1+1>2?
说实话,目前外界对Sora的细节还是未知的,现在也没有对公众开放,连waitinglit都没有开放,只邀请了业界和设计界的极少数人来使用,产出的视频也在网上都公开了。对于技术,更多是基于OpenAI给出的效果视频的猜测和分析。OpenAI在发布Sora当天给出了一个比较模糊的技术解释,但中间很多技术细节是缺失的。
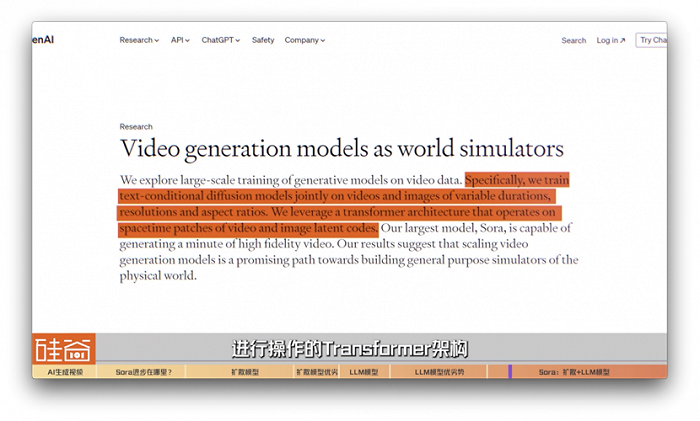
但我们先从Sora公开的这篇技术解析,来看看OpenAI的扩散+大语言模型技术路线是如何操作的。
Sora在开头就说得很清楚:OpenAI在可变持续时间、分辨率和宽高比的视频和图像上“联合训练文本条件扩散模型”(text-conditional diffusion models)。同时,利用对视频和图像潜在代码的时空补丁(spacetime patches)进行操作的Transformer架构。
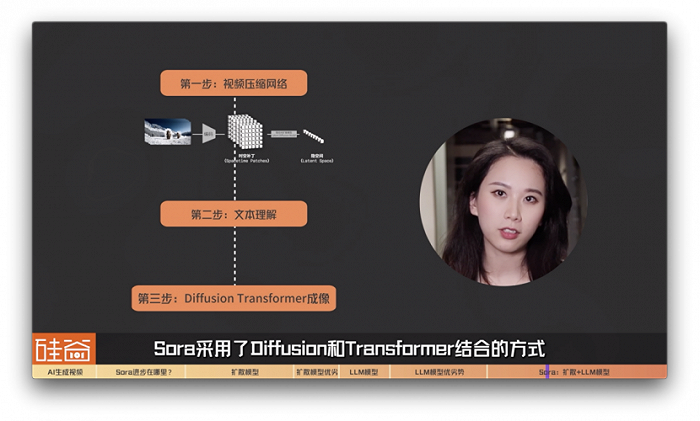
所以,Sora模型的生成的步骤包括:
第一步:视频压缩网络
在基于大语言模型的视频生成技术中,我们提到过把视频编码成一个一个离散的token,这里Sora也采用了同样的想法。视频是一个三维的输入(两维空间+一维时间),这里将视频在三维空间中均分成一个一个小的token,被OpenAI称为“时空补丁”(spacetime patches)。

第二步:文本理解
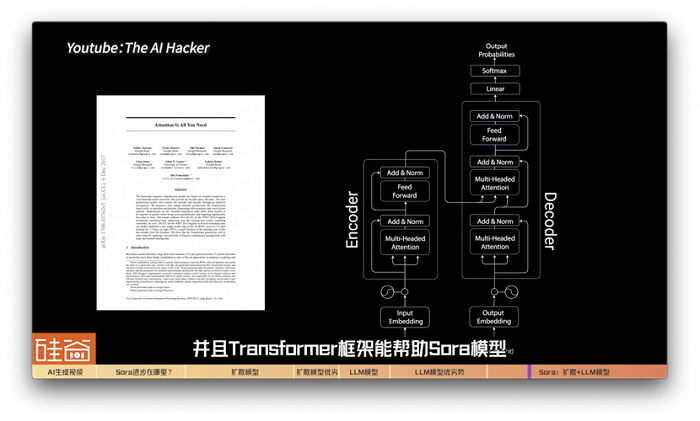
因为Sora有OpenAI文生图模型DALLE3的加持,可以将许多没有文本标注的视频自动进行标注,并用于视频生成的训练。同时因为有GPT的加持,可以将用户的输入扩写成更加详细的描述,使得生成的视频获得更加贴合用户的输入,并且transformer框架能帮助Sora模型更有效地学习和提取特征,获取和理解大量的细节信息,增强模型对未见过数据的泛化能力。

比如说,你输入“一个卡通袋鼠在跳disco”,GPT会帮助联想说,得在迪厅,带个墨镜,穿个花衬衫,灯光闪耀,背后还有一堆各种动物,在一起蹦跶,等等等等来发挥联想能力解释输入的prompt。所以,GPT能展开的解释和细节丰富程度,将会决定Sora生成得有多好。而GPT模型就是OpenAI自家的,不像其它AI视频startup公司需要调用GPT模型,OpenAI给Sora的GPT架构的调取效率和深广度,肯定是最高的,这可能也是为什么Sora会在语义理解上做得更好。
第三步:Diffusion Transformer成像
Sora采用了Diffusion和Transformer结合的方式。
之前我们在基于大语言模型的视频生成技术中提到过Transformer具有较好的可拓展性。意思就是说Transformer的结构会随着模型的增大,效果会越来越好。这一特性并不是所有模型都具备的。比如当模型大到一定程度时,卷积神经网络性能受模型增大带来的增益会放缓甚至停止,而Transformer仍能持续增长。
很多人会注意到,Sora在保持画面物体的稳定性、一致性、画面旋转等等,都表现出稳定的能力,远超runway,Pika,Stable Video等基于Diffusion模型所呈现的视频模型。
还记得我们在说扩散模型的时候也说道:视频生成的挑战在于生成物体的稳定性一致性。这是因为,虽然Diffusion是视频生成技术的主流,但之前的工作一直局限在基于卷积神经网络的结构,并没有发挥出Diffusion全部潜力,而Sora很巧妙的结合了Diffusion和Transformer这两者的优势,让视频生成技术获得了更大的提升。
更深一步说,Sora生成的视频连续性可能是通过Transformer Self- Attention自注意力机制获得的。Sora可以将时间离散化,然后通过自注意力机制理解前后时间线的关系。而自注意力机制的原理就是每个时间点和其他所有时间点产生联系,这是Diffusion Model所不具备的。

目前外界有一些观点猜测,在我们之前说到的扩散模型的第三步骤中,Sora选择将U-Net架构替换成了Transformer架构。这让Diffusion扩散模型作为一个画师开始逆扩散、画画的时候,在消除噪音的过程中,能根据关键词特征值对应的可能性概率,在OpenAI海量的数据库中,找到更贴切的部分,来进行下笔。
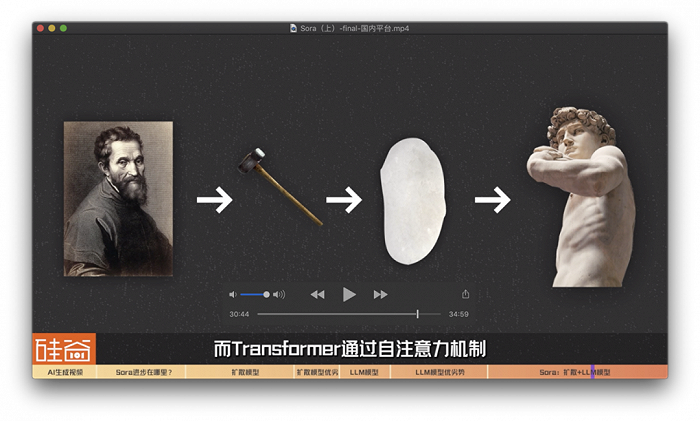
我在采访另一位AI从业者的时候,他用了另外一个生动的例子解释这里的区别。他说:“扩散模型预测的是噪音,从某个时间点的画面,减去预测的噪音,得到的就是最原始没有噪音的画面,也就是最终生成的画面。这里更像是雕塑,就像米开朗基罗说的,他只是遵照上帝的旨意将石料上不应该存在的部分去掉,最终他才从中创造出伟大的雕塑作品。而Transformer通过自注意力机制,理解时间线之间的关联,让这尊雕塑从石座上走了下来。”是不是还挺形象的?
最后,Sora的Transformer+Diffusion Model将时空补丁生成图片,然后图片再拼接为视频序列,一段Sora视频就生成了。
说实话,Transformer加扩散模型的方法论并不是OpenAI独创的,在OpenAI发布Sora之前,我们在和张宋扬博士今年一月份采访的时候,他就已经提到说,Transformer加扩散模型的方式已经在行业中开始普遍的被研究了。
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
目前又能看到一些把transformer的模型做到跟diffusion结合,然后效果可能也不差,甚至可能论文里面有些说的可能会更好。所以说这个东西我不确定以后模型会怎么发展,我觉得可能是两者结合的一种方式。就是transformer他们那种,比如说它预测 下一个视频,有天然的优势,就是它可以预测变成的一些东西。diffusion虽然质量高,但是diffusion目前很多做法还是生成固定帧数的。怎么把两个东西结合在一起,是一个后面会研究的一个过程。
所以,这也解释了为什么OpenAI现在要发布Sora,其实在OpenAI的论坛上,Sora方澄清说,Sora现在并不是一个成熟的产品,所以,它不是已发布的产品,也不公开,没有等候名单,也没有预计的发布日期。

外界有分析认为,Sora还不成熟,OpenAI算力也不一定能承受Sora被公开,同时还有公开之后的假新闻安全和道德问题,所以Sora不一定会很快正式发布,但因为transformer加diffusion已经成为了业内普遍尝试的方向,这个时候,OpenAI需要展示出Sora的能力,来在目前竞争日益白热化的生成式AI视频领域中重声自己行业的领先地位。
而有了OpenAI的验证之后,我们基本可以确定的是,AI视频生成方向会转变到这个新的技术结合。而OpenAI在发表的技术文章中也明确指出,在ChatGPT上的巨量参数“大力出奇迹”的方式,被证明在AI视频生成上。

OpenAI在文章中说,“我们发现,视频模型在大规模训练时表现出许多有趣的涌现功能。这些功能使 Sora 能够模拟现实世界中人、动物和环境的某些方面。

这说明,Sora和GPT3的时候一样,出现了“涌现”emergence,而这意味着,与GPT大语言模型一样,AI视频也需要更多的参数,更多的GPU算力,更多的资金投入。
Scaling,依然是目前生成式AI的绝招,而这可能也意味着,生成式AI视频也许最终也会成为大公司的游戏。
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
我觉得可能更直观的就是相当于你,比如说你一个视频可能存下来是几十个GB,然后可能到大语言模型就得大一千倍了,就得上TB了,就是大概是这么个意思,但是我觉得应该是能看到这样一个趋势的,就是就虽然现在视频的参数量只是在billion级。
但是像图片里面他们之前stable diffusion模型,他们后来出了一个stable diffusion XL,他们也是把模型做大了,然后也带来了一些比较好的一个效果,也不是说比较好的效果,就是他们能做更真实的那图片,然后效果也会更明显一些。我觉得这是一个趋势,就是未来肯定会把参数量做大的,但是说它带来的增益会有多少,也取决于你目前的这个模型的结构以及你的数据量,你的数据是什么样的。
以上是我们对Sora非常初步的分析,再次说明一下,因为Sora非常多技术细节没有公开,所以我们的很多分析也是从外部视角去做的一个猜测,如果有不准确的地方,欢迎大家来纠错,指正和探讨。
评论