

文|三易生活
即日起ChatGPT即开即用、不再需要注册了,当地时间4月1日,OpenAI方面在X平台上宣布了这一消息。而且在未登录状态下,使用的ChatGPT与普通用户一样都是基于GPT-3.5 Turbo。由于OpenAI官宣这个消息的时间节点颇为微妙,以至于有相当多网友认为这只是愚人节的玩笑,但官网实实在在的变化证明这次OpenAI并没有开玩笑。
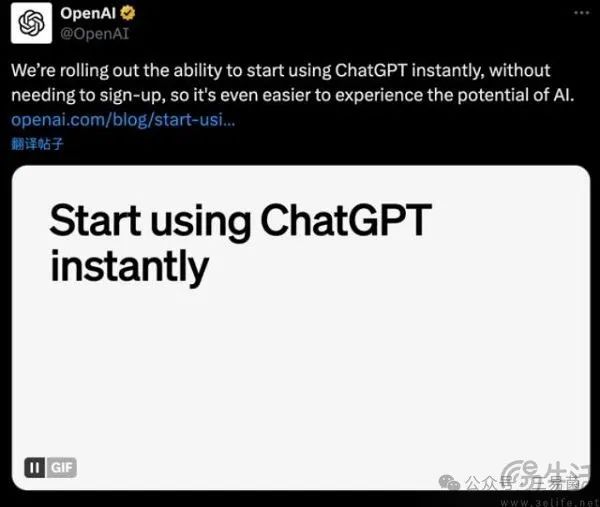
用OpenAI的话来说,每周有超过1亿人使用ChatGPT学习新知识、寻找创意灵感,或获得问题的答案,逐步推出这一产品的目的,是让任何对其功能感兴趣的人都能使用人工智能。需要注意的是,未登录用户是使用的ChatGPT是“丐版”,无法获得保存或分享聊天记录、使用自定义指令、解锁语音对话等高级功能。此外,未登录用户通过ChatGPT获得的回复会引入额外的内容保护措施,例如拒绝生成有害内容。
我们在实际体验后,发现了一个OpenAI没有在新闻稿中透露的事实,那就是ChatGPT似乎会区别对待访客和注册用户。对于未登录的访客用户,ChatGPT会针对问题给出结论、并附带简短的解释,而面对注册用户,ChatGPT则会用更详细、更透彻的解释来论证输出的结果。
从某种程度上来说,未登录用户看到的ChatGPT更像是一个AI搜索引擎、而非聊天机器人,这或许就是OpenAI的目的之一。

那么ChatGPT破圈了吗?作为史上最快突破1亿月活用户的互联网产品,它毫无疑问是成功的,但要说“破圈”,ChatGPT似乎确实还差一口气。因为在上线半年之后,无论是来自SimilarWeb的流量统计,还是百度、谷歌的搜索指数,都表明ChatGPT进入了持续下滑的状态。而出现这一现象的原因其实很简单,ChatGPT这类AI大模型工具与相关厂商宣传的样子是有落差的,它不仅需要门槛、也没那么好用。

热衷探索未知的极客,以及对新技术感兴趣的爱好者,通常会对ChatGPT赞不绝口,可更多的普通用户则往往会在尝试之后敬谢不敏。事实上,ChatGPT在C端用户中的实际渗透率,与它所拥有的偌大名声并不那么匹配。相较向B端用户出售API和Token,ChatGPT在C端的Plus订阅服务只能称得上是聊以自慰,其现状更是不足以支撑OpenAI“AI像手机那样改变世界”这样的愿景。
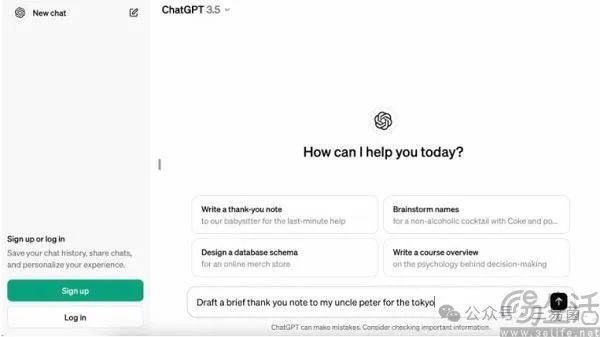
一直以来,账号体系都是互联网行业的基石之一,是用户体验互联网厂商服务的凭证,也是这些厂商的重要资产,所以互联网厂商总是会要求用户在使用前需要先注册。而OpenAI现在不强制要求用户注册,也就意味着用户可以像使用搜索引擎一样来使用ChatGPT。
尽管Sam Altman嘴上说着,“挑战谷歌搜索地位非常无聊”。但实际上,OpenAI在新闻稿所展示的DEMO中的“How can I help you today”,就已经表明了他们确实试图将未登录用户看到的ChatGPT,打造成AI搜索。
搜索引擎能够成为如今互联网行业的基础设施,靠的是零门槛所带来的普惠性,所以OpenAI此举只不过是在照猫画虎。事实上,也正如OpenAI预料的那样,暂未全球开放无需登录的ChatGPT,就已经被大量涌入的网友给搞崩了。也就是时隔一年半,正当Gemini 1.5、Claude 3争奇斗艳之际,ChatGPT再次回到了“C位”。
但除了为ChatGPT的热度再添一把火之外,OpenAI此次开放ChatGPT,或许还想着要薅未登录用户的羊毛。
未登录用户默认允许将对于数据提供给OpenAI,作为ChatGPT改进大模型的语料。在现阶段,AI行业最大的危机是网络上的现有信息量可能已经不足以支撑AI厂商训练更先进的AI模型了。如今语料的价值早已被明确,握有相关资源的企业更是无不待价而沽。比如Reddit就把自家用户的数据以6000万美元/年的价格卖给了谷歌,而诸如新闻媒体等担忧生成式AI会来抢饭碗的行业,则是旗帜鲜明地在反对AI。
高质量文本数据会在未来两到三年出现供给匮乏的状态,已经在业界得到了广泛的认可。例如Meta创始人扎克伯格在宣传自家AI研发能力时就曾宣称,通过Facebook和Instagram等平台拥有的大量数据,为其AI研发提供了重要优势。但相较亚马逊、谷歌、Meta、苹果等传统巨头,当下处于AI赛道领头羊位置的OpenAI,却反而缺乏稳定的数据供给渠道。
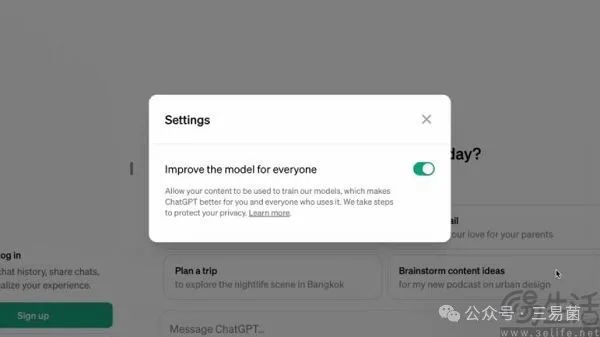
要知道根据相关机构估测,GPT-4训练涉及的数据量就高达12万亿Tokens,尚未问世的GPT-5则可能需要60万亿到100万亿Tokens。AI大模型进行预训练时的初始训练集固然重要,但其与用户真正开始交互之后产生的数据,对于大模型性能的提升更为关键。事实上,为了说服未登录用户贡献数据,OpenAI甚至用上了“Improve the model for everyone”、这种堪称道德绑架的说辞。
所以无论是出于扩大ChatGPT影响力,还是获得更多用户的交互数据来训练出更强大的AI大模型,彻底开放ChatGPT对于OpenAI来说都是百利而无一害。
评论