

文|数智前线 周享玥
编辑|徐鑫
为了能让自己以后更好地摸鱼,我上周第一次和大模型协作,完成了对一份财报的分析。
事情是这样的:前不久我与多位职场人士聊了聊大模型推出一年后,他们的真实使用情况。参见《大模型下众生相:焦虑者、使用者和弃用者》。我也在小红书上看到,不少大学生用AI给论文降重。这激发了我的一个想法,正巧赶上财报季,需要写大量财报分析,如果我当时用上了大模型助手,效率到底能够实现多大跃升?
于是,按照以往写财报的习惯,我同时使用了四个大模型C端助手,包括文心一言、智谱清言、kimi、通义千问,来试图模拟这个过程。
从和大模型协作的过程和结果看,我有了几点感受:
1、大模型的确能节省时间,前提是熟练使用。这次全新的尝试中,我需要不断摸索,调试问法,寻找更好用的指令,还要确认AI输出的内容是否正确。因此协作花费的时间甚至比以往我单独完成多了好几倍。当然,我相信,下一次耗时会大幅缩减。

2、对于过去的信息,大部分情况下,可放心使用大模型产品的联网检索功能。这有助于提高自己的素材收集效率。
3、基于知识库的实时信息读取,大模型的结果只能作为参考,需谨慎确认,虽然它的确能迅速抓取关键数据、提供分析思路,但目前人和机器去协作还做不到十分顺滑,比如容易存在数据读取错误,“张冠李戴”的可能,无法让人完全信任其数据准确性。
4、提示词的专业性和精准度也会极大程度影响大模型的返回效果。学会更高明和易用的提问方法,有助于更顺畅地使用AI。
为了能获得更好的效果,我也有以下建议:给大模型赋予一个角色,提示词更为清晰和专业,偶尔可用AI帮写提示词,以及涉及数据的内容需重点确认。
01 “傻瓜式”用法,都能hold住
每逢财报季,财报分析稿件的撰写,都极其考验“抢时间”和“找角度”的能力。这不仅要求我在最短时间内,迅速从繁杂信息中,找到所需的关键业绩指标,还要与不同公司的业务情况相结合,拎出财报背后潜藏的一些关键信息。过程中,往往还会涉及到各种表格、趋势图的制作。
我希望,AI能简化这些流程,即便不能做到一步到位,至少也要省掉其中大量繁琐且不要求太多技术含量的工作。抱着这样的期望,我开始了探索。
从大模型的聊天机器人交互界面开始,我发现几家大模型厂商已经卷起来了。
不同于OpenAI只在收费的GPT 4中提供有文件上传的功能,ChatGPT 3.5无法直接上传文件(ChatGPT 3.5也能通过安装插件,实现文件上传,但不在此次试用范围内,未进行更多探索),目前,国内多家大模型推出的免费版本中,都已内置文件上传的功能,相当于可以直接上传一个“知识库”给到大模型,作为参考。
大模型厂商们甚至在可上传的文件数上“卷”了起来,比如通义千问“可同时上传100个文件”,kimi最多支持上传50个文件。

财报分析的第一步,就是要读懂财报。
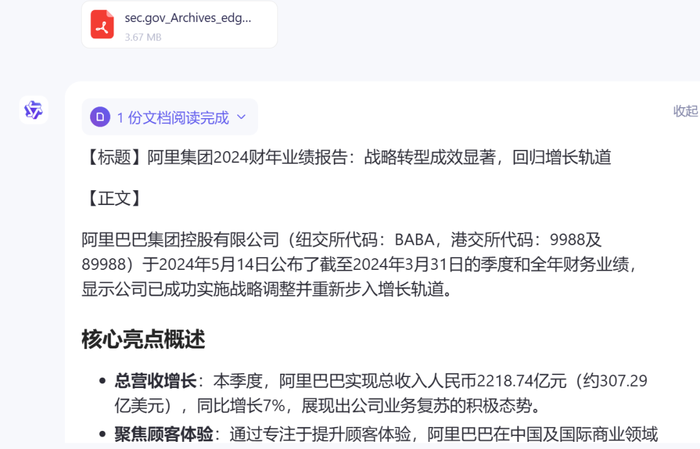
模拟这个场景,我决定,先用最“傻瓜式”的问法,直接将比亚迪“最新发布”的2024年一季报,丢给大模型,让AI参考文件中的各项信息,帮我写一篇财报分析稿,看AI是否已经能在读财报这件事上达到“一键即出”的水平。
这份财报,内容相对简单,主要涵盖三大财务报表及股东信息,并未涉及详细业务构成等其他更多元的信息。
几个大模型据此给出的财报分析文案,也都较为简洁明了,基本都涉及营收、净利润、现金流净额、非经常性损益等几个财报分析时的重点指标,但也不尽相同,一些大模型还对其他一些指标进行了分析,比如研发投入、股东回报、风险因素、股东及持股情况、资产负债情况、每股收益、净资产收益率等。
当然,如果AI仅仅能做到这一步,那对我的帮助算不得很大,要知道,财报发布后,直接打开雪球、东方财富网、Wind等各种专业的财经网站,这些信息也能迅速一览无余,而且比AI给出的更可信。毕竟,大模型偶尔会给出错误的数据,比如将百万亿元级别的数据,读成几十万亿元。

于是,我又尝试上传了阿里、腾讯两家在港股上市的最新财报,结果发现,随着可参考“知识库”中信息维度的丰富(三大财务报表之外,还涵盖了详细的业务构成,以及分部业务、财务表现等),几个大模型产品,也顺势在分析维度上进行了拓展,除了拎出关键财务指标,还更多在企业的“业务亮点”以及业务与财务之间的关系上进行了着重分析和展现。而这对于我来说,的确可以形成一些借鉴和参考。

不过,不同大模型的分析风格并不一样。
kimi、智谱清言、通义千问为我提供了“更多的数据,但更简洁的分析”。

文心一言则侧重展现自己的分析能力,数据提供更少,但分析更为深入、完善。

当然,除了A股和港股财报,我常常也需要读一些在美股等国外股市上市的公司的财报。我试图重开一个对话框,上传阿里在美股市场发布的英文版财报,几个大模型无一例外,都准确读出了里面的关键信息。事实证明,AI在读英文文档这件事上,比我做得更快更好一些。
总结这一轮的“傻瓜式”试用:
当我上传一个财报文档,目前各家大模型都能直接输出一篇“勉强及格”的财报分析稿,但内容相对简单,只是一些围绕直接能在财报中找到的指标的简单分析,目前还只适用于用来了解这家公司的简单情况,而无法达成对其深入剖析。甚至一些大模型,还会在数据的读取上出现问题。
不过,如果能在“问法和提示词”上更进一步,AI是否能帮助我完成一些更复杂的工作?
02 超出“知识库”,数据容易出问题
撰写财报分析类的稿件,少不了各种对比。横向和同行比,纵向和过去的自己比。
当然,如果你直接问AI,“2024年一季度,比亚迪的业绩情况,和同行业的其他竞争对手相比较,各自的表现如何”,大部分大模型产品都会告诉你,由于数据缺失,自己无法完成这项工作。

一些大模型也会给出更细致的提示。比如通义千问,告诉我需要在对比时重点关注几个关键指标,并详细分析了指标异常时可能代表的意义。

文心一言则将“喜欢假设”这点贯彻到了底,它试图通过“假设”,来向我演示该在哪些方面对比比亚迪和同行的情况。

不过,如果我采用“迂回”问法,先问比亚迪的竟对有哪些,几家大模型产品都能快速通过联网搜索结果,给出对应的公司名称及简要情况介绍。
进一步追问这些公司的业绩情况,一些大模型会建议我直接查阅每家公司的财报,一些大模型则陈列出了部分公司的部分业绩和销量。这些的确在一定程度上,有助于我完成比亚迪与行业内的其他公司的一个对比。

而当我需要纵向对比时,往往要比对一家公司过去几年的业绩变化。通常的做法是,打开雪球、Wind等专门的网站,找到对应的统计栏目,即可初步了解变化趋势。实在没有的,比如某个季度连续几年的变化,也能通过Excel等工具,输入数据后,进行处理。
现在,AI能够一步取代这些工作吗?
可以看到,接到任务后,几个大模型都很快给出了对应的分析架构,但大部分大模型产品却不可避免地在数据分析处理上出现了一些问题。
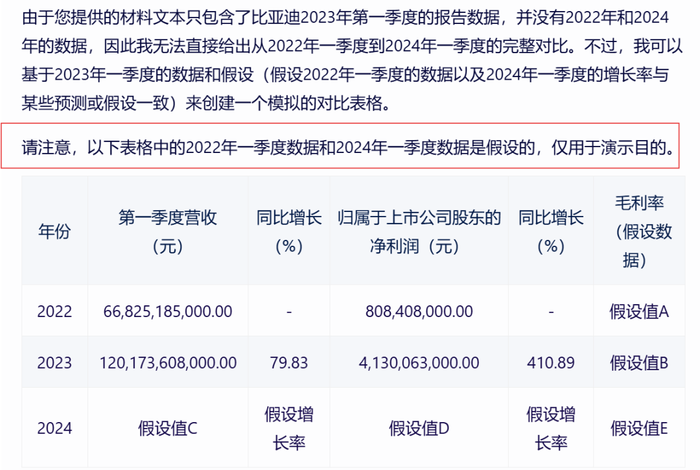
文心一言和kimi都“机智”地发现了2022年一季度数据的缺失,一个选择在分析时使用假设数据加以示例说明,一个明确指出“需参考历史财报”。
不过,在四个工具助手中,一个在读取小数位时犯了个小错误,不管是营收还是归母净利润都比实际数据少读了一个小数位。


一些大模型,产生了幻觉,给出了财报中没有且与真实情况相悖的同比增长数据。

也有大模型搞错了财报中数据与财季的对应关系,将2023年Q1和2024年Q1的数据分别“张冠李戴”到了他们的上一年。

为了纠正这些“幻觉”和错误,获得更准确的结果,我试图将比亚迪2022年一季报和2023年一季报也传给大模型,让它结合补充文件,进一步回答过去三年的变化趋势。
不出意外,有了新“知识库”的加持,尽管还有模型偶尔在一两个数据上出现错误,但整体来看,几个大模型的回答精准性都得到了提高,同时也给出了一份条理清晰的分析。当然,受限于一次只能上传一个文件的规定,文心一言给出的结论依然只针对一个文件进行了分析。

值得一提的是,kimi给出的回答中,除了详细列出了营收和归母净利润在过去三年的变化,并加以分析,还进一步给出了结论和建议,并指出如果要获得更全面的分析视角,还需考虑公司的成本结构、市场竞争状况、以及宏观经济和行业发展趋势等多方面因素。

我根据这一提示继续追问了kimi关于比亚迪过去三年成本结构的变化、研发费用和销售费用增长的原因等问题,其都能比较准确地找出对应数据,并给出一定的分析。
我同样将这些问题发给了其他几个大模型进行追问,一些大模型在原因归纳上较为擅长,可以为财报分析者提供一些分析思路,但在某些数据上,仍然容易出现财季与数据对应出错的问题。

大模型给出的分析,很多也会参考其联网搜索的结果。当然,大多数大模型并不会在给出的回答中指明哪些是联网获取,哪些是来自我上传的“知识库”。而通义千问经常会在给出的回答中,附上其参考的一些链接。

智谱清言和文心一言,则在我问到诸如“研发费用和销售费用为什么大幅增长”等一些问题后,在对话窗口推荐一些更细节的问题,帮助用户更具有针对性地提问。
一个阶段性小总结:
当涉及一些需要计算才能知晓结果,又或是需要额外提供补充数据的问题时,不少大模型在数据上出错的可能性大幅增加,除了常见的读错小数位的情况,一些大模型也会将指标和数据之间的对应关系搞错,又或者直接出现“幻觉”,“胡说八道”一些并不存在的数据。
不同的大模型企业在交互逻辑上侧重点也不太一样。一些大模型在产品交互中非常重视“免责声明”,如kimi,也有大模型产品在交互界面上非常重视用户友好度,比如智谱清言和文心一言的对话窗口都有问题推荐;一些大模型产品则重视答案的可信度,如通义千问总是在回答中提供自己参考的文献链接。
03 制表可以,作图不行
光有文字的对比分析还不够,要想更直观地反映出一家公司连续几年的业绩变化情况,表格或趋势图必不可少。
制表这件事儿,几个大模型看起来都十分地“游刃有余”,一接收到指令,“唰唰唰”几下,就把正确的表格样式,以及需要的数据从报表里找了出来。
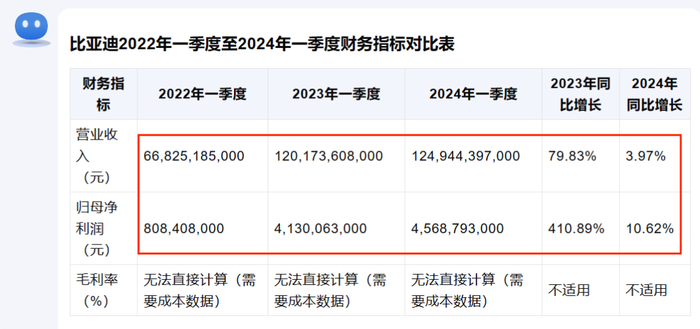
文心一言稍有不同,由于我上传的文档中,只能读取最近的一个,因此给出的是根据假设值来做的演示图表。
当然,对比营收、净利润等能直接在财报中找到的数据,像毛利率这样需要一些计算的数据,对大模型就稍微“有点难度”。一些大模型直接指出这一数据“未直接给出”,而一些大模型虽然根据其拥有的通识,正确列出了毛利率的计算公式,但计算结果却是错误的。
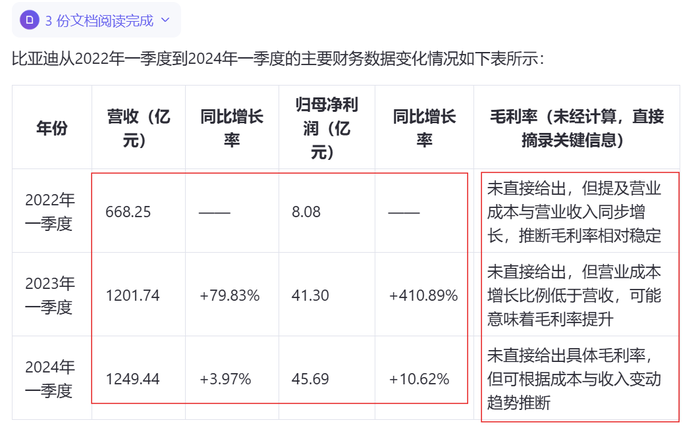
另外,单位的换算,也是大模型容易出错的地方。当我加了“单位用亿元”的限定后,四个大模型中有两个换算正确。
制表效果勉强可以,作图又如何?
面对进一步根据表格制作一个趋势图的要求,几个大模型均表示自己无法直接生成图形,但是可以提供一些指导和建议,帮助用户使用Excel或其他图表工具自行作图。

04 角色设定,起大用了
经过前面这些尝试,虽然勉强能通过与AI的协作,给我带来一些帮助,但过程还是太复杂了,准确性需要反复确认,分析的指标和角度也都较为简单。
如何才能给AI再提一下效?加一个“角色身份”的设定或许可以。毕竟,角色扮演正是大模型擅长的能力之一。
在问题前面增加“假定你是一个资深的财务分析人士,拥有丰富的股票投资和财报分析经验”这一表述后,果然,几个大模型给出的答案中所涉及的数据指标,均明显比没有角色限定时,更加多元和广泛。
尤其是文心一言,在这方面表现出了更多层次的观察视角,重点强调营收和归母净利润的变化的同时,也从业务结构、财务指标、风险因素等多方面进行了分析。

而当在给了大模型一个角色设定的基础上,再继续增添一些更专业和细化的指令时,大模型给出的回答的效果还能够进一步提升。
不过,值得注意的是,对于不同大模型,并不是一个指令即可通用。一些指令可能对于某个大模型,能大幅提升回答的专业性和准确性,但对于另一些大模型,可能效果提升并没有那么明显。
比如当我把一个将近3000字的指令,给到不同大模型时,kimi面对这个详细规定了财报分析过程中常用的杜邦分析法的具体细节,且要求了大模型在自己的“角色”设定下,根据规定“技能”,严格遵守“约束”,按“工作流”执行流程的指令,就表现出了很好的效果提升。用户给出指令后,只需按照AI返回的提示,一步步追问,就可简单且快速地了解财报分析中的各项关键数据。

而智谱清言、通义千问等虽然也按照这一指令规定,使用杜邦分析法进行了分析,但都是“一步到位”,并未详细对这一指令中的每一个要求进行详细分解和展示。

可以发现,更加专业的指令,的确可以大幅提升人与AI协作办公的效率。尤其是在财报分析这个领域,由于一份财报中含有大量信息,读起来往往费时费力,AI工具的应用,确实能在一定程度上帮助用户迅速找到财报中的关键数据,并实现相应指标的计算。
但专业性的指令,目前对于普通用户,仍然还是一个巨大的门槛。
有意思的是,一些大模型已经注意到这一点,并试图降低用户编写专业提示词的门槛。比如,文心一言专门在官网上设置了一个“使用指南”板块,并举了各种使用案例,作为“教程”,指导用户如何更快写出适合文心一言的指令。kimi则在kimi+中内置了“提示词专家”服务,通过AI来帮助用户编写提示词,用户只需将AI给出的提示词,再返回给AI,即可快速进行财报分析。

05 更专业的内容,仍需人工
通过更加专业的指令,让AI帮助分析人们普遍关注的财务指标问题,仍然不够,要想让一篇文章更具深度和广度,还需要去和具体的业务相结合,做更深一层的分析。
比如市场关注车企的一个指标——单车利润。
我试图向AI寻求这一数据,但即便给到大模型关于比亚迪年报中汽车与相关产品业务的业绩数据,以及当年的车辆总销量,依然很难计算出正确的单车利润。这些仍然需要专业的第三方机构按照专业的方法,核算给出。

不过,对于过去已有的单车利润信息,几个大模型产品均能通过联网搜索,快速获得。

综合来看,这也是目前AI所能提供的最为成熟的功能之一。它能帮助我在过往的各种繁杂的链接和信息中,快速筛选出符合我要求的关键信息,甚至能比参考实时上传的知识库给出的内容准确性更高。
当然,从上述的协作流程可以看到,目前AI能够为我的日常工作提供的助力,刚刚达到及格线水平。它能准确提供大量的过往参考信息,也能实时阅读文档,捕捉其中的关键信息,但这些都还是整个工作流程里最为基础的那部分。一旦涉及到略为复杂和需要专业性的地方,仍然需要人工介入,并且整体协作体验并不十分顺畅。
我还曾希望,AI能帮我发现一些目前被忽略但公司客观存在的问题,但还很难实现。
AI的能力仍然需要进步,AI的使用门槛依然很高,让AI帮我摸鱼的愿望还没有照进现实。
评论