

界面新闻记者 |
界面新闻编辑 | 宋佳楠
“今天这个震撼发布,明天那个史诗级更新,但是我要问,应用在哪里?谁从中获益了?”
7月4日,百度董事长李彦宏在世界人工智能大会(WAIC)的产业发展主论坛上狠批大模型刷榜比拼之风,称很多公司把关注点放在基础模型上,一天到晚跑分、刷榜,谁又超越GPT4了,OpenAI又出了sora、GPT4o等。
大模型刷榜,主要是指各家公司和研究机构竞相在各种基准测试上取得最高分数,以此来展示其模型的性能优越性。在追求高分的过程中,一些模型可能被训练于包含基准测试数据集的样本上,从而导致不公平的优势。
此外,一些基准测试可能过于简单或者不够全面,无法完全反映模型在复杂场景下的真实能力,也可能导致资源分配的不平衡。
在李彦宏看来,当前最重要的是应用,“没有应用,光有基础模型,不管是开源还是闭源都一文不值。”他呼吁,“不要卷模型了,要去卷应用。”

实际上,基于基础模型的应用已经逐渐在各行各业渗透。以快递行业举例,大模型能将订单处理时间从3分多钟缩短到19秒,解决90%以上的售后问题效率。而在代码生成领域,百度内部30%左右的代码,已经用AI生成,代码的采用率超过了44%。
据李彦宏透露,两个多月前文心大模型的日调用量超过了2亿,近期则超过了5亿。“调用量发生的变化体现了真实的需求,有人真的从大模型当中获益。”
但他也特别提醒,要避免掉入“超级应用陷阱”,“DAU 10亿的APP才叫成功”已经是移动互联网时代的思维逻辑。AI时代下,“超级能干”的应用比只看DAU的“超级应用”更重要,只要对产业、对应用场景能产生大的增益,整体价值就比移动互联网大。
百度内部看好的AI应用发展方向是智能体,制作好的智能体比互联网时代制作网页还要简单。未来在医疗、金融、教育、制造、交通、农业等领域,都会依据自己的场景、特有的经验、规则、数据等等,做出各种各样的智能体。
“将来会有数以百万量级的智能体出现,形成庞大的智能体生态。”李彦宏说。
对于行业热议的开源和闭源之争,他再次表达了自己的看法,称有些外行混淆了模型开源和代码开源。在他看来,同样参数规模之下,闭源模型的能力比开源模型更好,开源想要追平闭源模型的能力,需要有更大的参数,这意味着推理成本会更高,反应速度会更慢。
“开源模型并不能让你站在巨人的肩膀上去迭代和开发。”他说,有公司通过开源模型来改款,只是创造一个孤本模型,无法从基础模型持续升级当中获益,也无法共享算力。开源模型只在学术研究、教学等少数领域有价值,并不适合大多数应用场景,尤其是处在激烈竞争的市场环境中,要让公司的业务效率、成本优于同行,商业化的闭源模型是最能打的。
不过,也有业内人士向界面新闻表达了不同意见,认为李彦宏闭源大模型的言论只是站在百度的利益之上,开源模型有其商业价值,尤其从长远来看,开源模型的能力会不断追平闭源模型。
开闭源模型之争只是国内“百模大战”的一隅。按照李彦宏的观点,大战造成了社会资源的巨大浪费,尤其是算力浪费,但另一方面,使得中国开始追赶世界上最先进的基础模型。
上述种种言论背后,也在一定程度上反映出百度想要改变现状的迫切。
在上一轮移动互联网竞争中,百度不断“掉队”,转而选择押宝AI。而在这一轮的AI角逐战中,不仅有老牌互联网大厂,还有大模型创业明星公司,竞争更加激烈。
即使在百度最为强势的搜索领域,也不得不面对竞争对手的“蚕食”——不仅盘踞着微信搜索、小红书的内容搜索,各家大模型公司都推出了AI搜索,例如Kimi、豆包、海螺AI、智谱清言等产品。搜索,已成为当下大模型消费端应用的必争之地。
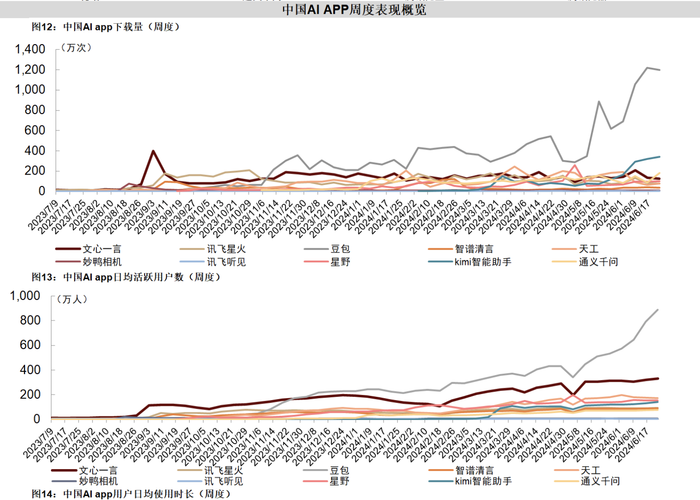
至少在声量上,百度已有所落后。中金最新发布的研报显示,Kimi在3月份爆火后,一直领先于百度的文心一言,拿下中国AI网站流量第一名。
以6月19日至25日这一周为例,中国AI网站的周度访问量中,月之暗面旗下的Kimi chat以571.83分居于榜首,文心一言以412.97分居于第二名;而在中国Al app下载量以及日均活跃用户数榜单中,字节跳动旗下的豆包成为断层第一,百度始终居于后位。
如何在后续的竞争中持续保持优势,并实现突围,将是李彦宏和百度需要共同面对的课题。
评论