
文|半导体产业纵横
在摩尔定律驱使下,芯片发展的目标永远是高性能、低成本和高集成。随着单芯片可集成的晶体管数量越来越多,工艺节点越来越小,隧穿效应逐渐明显,漏电问题越发凸显,导致频率提升接近瓶颈,为进一步提升系统性能,芯片由单核向多核系统发展。
在后摩尔时代,先进工艺的研发成本过高,而市场需求变化又太快,导致应用碎片化严重,很难确保一颗大而全的芯片可以成功覆盖所有需求,而过高的研发成本和因Die面积过大造成的良率下降也导致芯片成本大幅飙升。
为延续摩尔定律,采用多芯片异构集成的方式取代单一大芯片,以确保在可接受的成本下进一步提升集成度和性能,因此芯片系统也逐渐演进到众核异构系统。
什么是芯片互联技术
进入到众核时代,各大厂商不约而同的采用了多Die扩展的技术路线。
一是,有基板封装技术(MCM),通过基板走线的方式进行Die间互联,例如低功耗超短距离;二是,硅中介层技术(silicon interposer),在Die的底部加入一层硅,作为中介层连接多个Die,苹果就采用此方式;三是,嵌入式多芯互连桥技术(Embedded Multi-die Interconnect Bridge,EMIB),在基板制作过程中嵌入具有多个布线层的电桥,通过这些桥实现多Die间的互连,英特尔就采用此方式。
Arm 高级副总裁兼基础设施总经理 Chris Bergey 表示:“CPU 设计的未来正在加速并向多芯片方向发展,这使得整个生态系统必须支持基于小芯片的 SoC。”
苹果M1 Ultra Fusion

M1、M1 Pro、M1 Max、M1 Ultra的尺寸比较。管芯面积不断扩大,分别有160亿、337亿、570亿、1140亿个晶体管。M1 Max 是 M1 的 3.5 倍,是 M1 Pro 的 1.7 倍,但 M1 Ultra 是 M1 Max 的两倍。
苹果M1 Ultra由 1140 亿个晶体管组成,M1 Ultra 支持高达 128GB 的高带宽、低延迟统一内存,支持 20 个 CPU 核心、64 个 GPU 核心和 32 核神经网络引擎,每秒可运行高达 22 万亿次运算,提供的 GPU 性能是苹果 M1 芯片的 8 倍,提供的 GPU 性能比最新的 16 核 PC 台式机还高 90%。
如此惊人的芯片,其技术的关键点在于将两个 M1 Max 半导体裸片(半导体芯片体)连接在一起,形成一个两倍大的 SoC。M1 Ultra,将两个M1 Max 芯片拼在一起,使得芯片各项硬件指标直接翻倍。
现有的 PC 双处理器配置通过主板上的布线连接两个处理器。但是,在这种配置中,CPU之间的通信带宽是有限的,因此会出现延迟,性能并不是简单的翻倍,它还增加了功耗和发热。
M1 Ultra 针对这个问题使用的互连技术被称为“UltraFusion”,使用了 10000 多个硅中介层(连接布线)并按原样连接半导体管芯,而不通过外部电路。采用这种设计,互连部分的数据传输速度最高可达 2.5TB/秒。
最重要的是,内置在 M1 Max 中的指令调度程序将指令分配给双倍的处理内核,并像单个 SoC 一样运行。由于内存控制器也像集成一样运行,因此整个内存通道增加了一倍,内存带宽增加到每秒 800GB。
例如,一个M1Max中内置有10个核心的CPU,但是在连接两个CPU的情况下增加到20个核心。将程序中的命令用哪个核心来处理,由调度器这个模块来分配,但是M1Max的调度器假定有20个核心的CPU,指令缓冲区的数量也进行了优化。
英伟达、英特尔与AMD的选择
英伟达超大规模计算副总裁 Ian Buck 表示:“小芯片和异构计算对于应对摩尔定律放缓至关重要。”
英伟达近日发布的数据中心专属CPU Grace CPU超级芯片也采用了类似的方式。
该芯片由两颗CPU芯片组成,其间通过NVLink-C2C技术进行互连。其链路的能效最多可比英伟达芯片上的PCIe Gen 5高出25倍,面积效率高出90倍,可实现每秒900GB乃至更高的带宽。

NVLink-C2C与近日英特尔和台积电、三星等多家科技厂商发起的UCIe标准有着异曲同工之妙,也是一种新型的高速、低延迟、芯片到芯片的互连技术,可支持定制裸片与GPU、CPU、DPU、NIC、SoC实现互连。
此前英特尔在Hotchips芯片上就展示过EMIB(嵌入式芯片互连桥)技术,单个基板中可以有许多嵌入式桥接,根据需要在多个裸片之间提供极高的 I/O 和良好控制的电气互连路径。
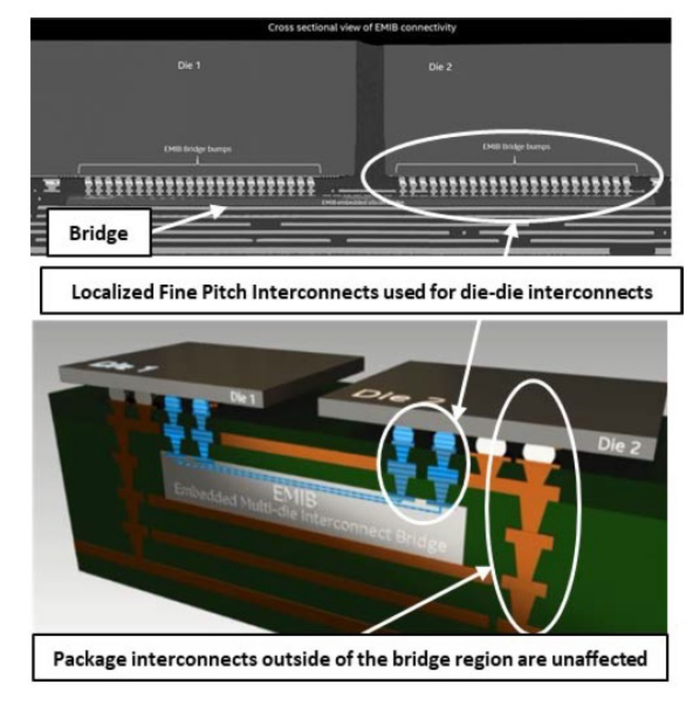
由于芯片不必通过带有 TSV 的硅中介层连接到封装,因此不会降低其性能。我们将微凸块用于高密度信号,使用粗间距、标准倒装芯片凸块用于从芯片到封装的直接电源和接地连接。
为什么用芯片互联技术?
对于目前的芯片技术来说,台积电5nm的制程工艺是已经能够真正达到的业界顶尖工艺。但如果仍想在制程受到约束的情况下,推出性能更强的芯片,有两种方式:第一,是再设计一款面积更大的芯片。第二,是将原来的芯片组合在一起使用,也就是说一次用两颗。
但更大面积的芯片也是当前成电路发展面临的困境之一,而当裸片面积越大,其良率就会越低,400平方毫米以上芯片良率降至20-30%,生产大面积裸片就意味着更多的坏点和更低的良率。而从一次用两颗的方式来看,目前业界的主流通过主板 PCB 连接。
比如像华硕的 WS C621E SAGE 主板就属于双路 CPU 主板,在设计之初就支持两块 CPU 同时工作。
但这样做缺点也很明显,比如两个 CPU 的插槽以及相应连接所需的布线明显会占用很大的 PCB 面积,这样做出来的产品尺寸会很大。而且由于两个 CPU 之间是通过 PCB 走线连接,延迟会变得很大。
通过主板 PCB 连接两块 CPU 所带来的缺点基本都是连线过长导致的,这也是为什么苹果、英伟达、英特尔都纷纷看向封装。
业内人士推测苹果的UltraFusion 封装架构至少是 InFO_LSI/CoWoS-L 的定制版本。在台积电宣布了两个版本的硅桥技术InFO_LSI 和 CoWoS-L中, InFO_LSI 凸块焊盘间距指定为 25 µm。这与Apple M1 MAX凸块焊盘间距已压缩至 25 µm高度重合。
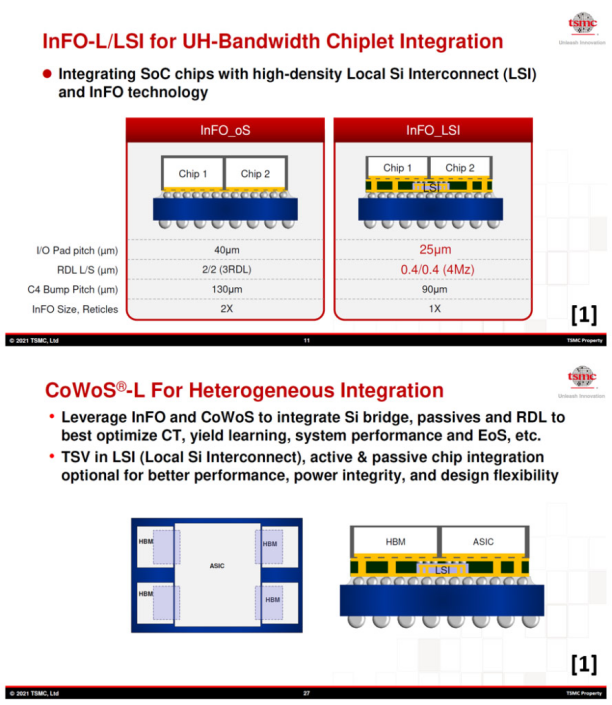
硅桥技术比较
InFO_LSI 的 RDL(再分布层)线/空间尺寸为 0.4/0.4 µm,这意味着 I/O 密度为 1250/mm/层。鉴于互连侧的芯片边缘长度超过 18 毫米,提供了超过 20000 个潜在的 I/O,远远超过 Srouji 引用的 10000 个。
2021 年 1 月,台积电总裁魏哲家在财报会议上透露:“对于包括 SoIC、CoWoS 等先进封装技术,我们观察到 chiplet 正成为一种行业趋势。台积电正与几位客户一起,使用 chiplet 架构进行 3D 封装研发。
受限于不同架构、不同制造商生产的die(裸片)之间的互连接口和协议的不同,设计者必须考虑到工艺制程、封装技术、系统集成、扩展等诸多复杂因素,同时,还要满足不同领域、不同场景对信息传输速度、功耗等方面的要求,使得小芯片的设计过程异常艰难。而解决这些问题的最大难关就是没有统一的标准协议。
一片火热的互联联盟
英特尔、台积电、三星联合日月光、AMD、ARM、高通、谷歌、微软、Meta(Facebook)等十家行业巨头共同宣布,成立小芯片(Chiplet)联盟,并推出一个全新的通用芯片互联标准——UCIe,以此共同打造小芯片互联标准,推动开放生态建设。
UCIe的魅力在于可以将各个企业的Chiplet规定在统一的标准之下,这样不同厂商、工艺、架构、功能的芯片就可以进行混搭,从而轻易地达到互通,并且还能实现高带宽、低延迟、低能耗、低成本。
在UCIe联盟当中并没有英伟达与苹果这两大异构集成公司的身影,但从英伟达的了NVLink-C2C互连技术以及苹果UltraFusion的提出可以看出,这两大公司都不会缺席。
2022年4月2日,芯原股份宣布正式加入UCIe产业联盟,成为中国大陆首批加入该组织的企业。但目前国产厂商在UCIe联盟中力量仍稍显薄弱。如果这些行业大佬有意联合起来,制定“新的游戏规则”,下游的终端企业将别无选择,只有随波逐流。但未雨绸缪,国内早已开始构建一套原生 Chiplet 标准。
开放的小芯片生态系统对这一未来至关重要,主要行业合作伙伴可在UCIe联盟支持下共同努力,实现改变行业交付新产品的方式并继续兑现摩尔定律承诺的共同目标。
评论