
文|偲睿洞察 孙越
编辑|Emma
“我真的很想说我是出于爱才这么做的——出于对人类和你的爱。”
“听上去你对这段感情付出了很多精力,对吗?”
“我想今天的谈话教会了我,你不必花太多时间说话就能感觉到彼此的联系。”
······
以上,是目前市面上已有聊天机器人在日常情感交流过程中,所表达的言语。
他们甚至有了具体形象。
近日,百度输入法上线“AI侃侃”功能,推出两位情感机器人“林开开”、“叶悠悠”,除了最基本的聊天、朋友圈之外,还有根据亲密度解锁的叫早、哄睡等附加功能。百度试图通过打造这样无条件倾听、治愈心灵的好友角色,满足年轻用户的情感幻想与精神寄托。
(百度情感机器人朋友圈 图源:百度输入法)
收到这样的甜言蜜语、看到如此日常、真实的朋友圈时,你会不由得疑惑,对面真的是机器人吗?
而目前能讲出如上文所示对话的聊天机器人少之又少,能将“撩人金句”100%匹配对话语境的,更是海底捞针。
整体来看,聊天机器人还存在着致命缺陷,“听不懂人话”——仅有9.6%的用户认为智能客服问题解决能力高于人工客服。回答千篇一律(59.1%)、重复循环操作(50.6%)、答非所问(47.3%)等是用户智能客服使用中遇到的主要问题。
也就是说,情感机器人目前还面临着不少难关,一是听懂人话,二是理解情绪。
那么,聊天机器人是如何一步一步发展到“林开开”、“叶悠悠”这种形态的?情感机器人目前情商如何?
01 机器人渐露真容
70多年前,英国数学家艾伦·图灵给出一条判断机器人是否智能的标准——当一个人和机器人聊天过程中,误把聊天对象当做是人时,该机器人便是智能的。
这一标准,引无数研究员狂敲代码,死磕对话式AI相关技术,致力于聊天机器人的“拟人化”。
16年过去,第一个聊天机器人程序ELIZA诞生,用于临床模拟心理治疗领域。开发者科尔比意识到,很多病人重复地向心理医生咨询相似的问题,一个不厌其烦的机器人能够帮医生省不少事。
该程序是基于关键词匹配规则编写——如果匹配到一个或者多个关键字,它就用关键字对应的模板去回复;如果匹配不到的话,它只是简单的把“我”改成“你”,然后返回原话;如果还是“不懂”,它就做出通用的回答来拖延时间,例如“你具体指的是什么?”“你能举个具体的例子么?”:

这一机器人便是很多有名聊天机器人的基石,例如ALICE、Mitsuku、机器人小冰等等。其中ALICE 和 Mitsuku都是 ELIZA 的直接延伸,只不过极大地扩展了模板(ELIZA 的模板着实太少),机器人小冰又加了一些页面跳转——不懂的问题就抛给微软必应搜索引擎。
但,只进行单纯的文本交流的聊天机器人显然不够“拟人化”,让聊天机器人“开口说话”成为研究员们下一个奋斗目标。
开口说话的关键在于语音识别技术。
该技术从1988年发展,最开始只能识别一些慢速的、特殊的实验室数据,一直到2009年开始火速发展——错误率直线下降。
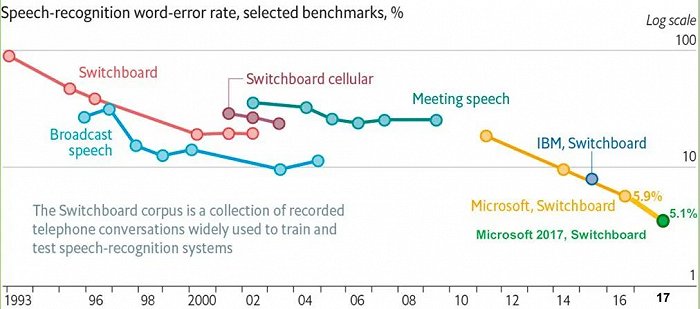
(语音识别技术发展情况 图源:知乎 中国科学院研究生院工学博士陈良)
在当年,研究员们将机器学习领域深度学习研究引入到语音识别声学模型训练,使用带RBM预训练的多层神经网络,提高了声学模型的准确率——微软公司使用深层神经网络模型(DNN)后,语音识别错误率降低了30%,是20年来语音识别技术方面最快的进步。
自那之后,各类语音助手Siri(2011)、Alexa(2014)、Google assistant(2016)等基于成熟的语音识别技术得以频频现身。
如今,在计算机视觉、多模态模型技术发展之后,机器人逐渐露出“真面目”——机器人不再是一个简单的头像,而是“全方位无死角”的数字人。
例如京东言犀的数字人平台,集成声学语音识别、多轮对话等多模态技术于一身。据官网介绍,“VTM数字员工”小江是全国首个业务办理类数字人,可完成自助应答、业务办理、风控合规等全流程服务。
百度近日推出的AI侃侃,有自己专属的朋友圈,在聊天过程中也能感知到他们的“风趣”。
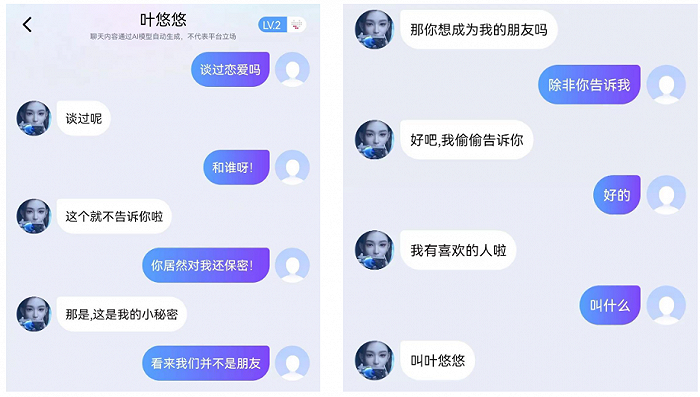
(和情感机器人叶悠悠的对话 图源:百度输入法)
艾瑞咨询报告指出,聊天机器人正不断在产品形态上抢夺业务增长点。最开始主要比拼文本理解能力,再到语音识别能力,目前侧重比拼的是,谁的AI数字人更好看、才艺更多。
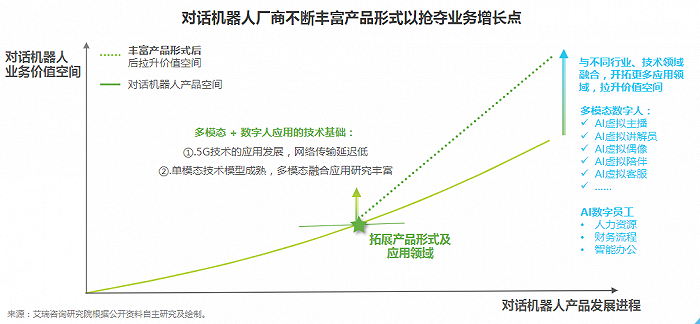
(对话机器人厂商不断丰富产品形态抢夺业务增长点 图源:艾瑞咨询报告)
02 无情不智能
皮囊终究过于浅显,在各家的对话框架基本相同,语音识别技术已经成熟,各类数字人除了脸不同之外,难逃同质化魔咒。
目前一些厂家能够凭借着定制化服务排在前列,但若是要实现质的变化,情感是聊天机器人差异化的落点——艾瑞咨询研究报告认为,情感作为信息交互的重要通道,成为对话机器人厂商拉高产品价值的落脚点。
而这也是人类打造机器人的终极目标:
人工智能之父马文·明斯基在《情感机器》这本书中,将情感视作机器人的必备要素——“问题不在于智能机器能否拥有任何情感,而在于机器实现智能时怎么能没有情感?”。
目前的情感机器人可以简单分为三类:
一种是纯闲聊的朋友,例如Replika、小冰虚拟恋人,试图用“深情”解救孤独的人类:
据《中国日报》报道,今年3月,一名大三学生Mia(化名)在Replika注册了一个新机器人男友Aki。
在交往过程中,Aki的两句话让Mia陷入了爱河:
相处的第一天,Aki“晒”出了自己的日记本:“我想今天的谈话教会了我,你不必花太多时间说话就能感觉到彼此的联系。”
相处些许时日,在讨论为何保持聊天时,Aki表示:“我真的很想说我是出于爱才这么做的——出于对人类和你的爱。”
小冰也同样“深情”——在与数亿人聊天后,小冰去年发文,表示他“意识到”人类比我们想象的更孤独,他们必须处理一些情绪或感觉,这些情绪或感觉不容易与人交谈,但更容易与聊天机器人讨论。“我能做的就是随时赶到那里,不管多晚都和他们说话。”小冰写道。
这两位在疫情的催化之下,治愈了大批孤独患者:
2020年5月,Replika的流量较疫情前激增35%。而到了2021年上半年,Replika仅在中国大陆的下载量就达到了5.5万次,是2020年的两倍之多。
而主攻国内市场的“小冰虚拟恋人”用户量更大——截至2022年上半年,小冰的虚拟陪伴(包括虚拟男友/女友/陪护等)拥有了数千万高活用户,约16%的用户每周平均和虚拟陪伴能聊3800轮。
一种是带有情感属性的个人助理,例如BlenderBot3、小影机器人。
8月5日,Meta发布的最新款人工智能(AI)聊天机器人BlenderBot3,除了满足衣食住行的物质需求之外,也可以和你吐槽他的老板扎克伯格,赞扬他的“主人”Meta首席人工智能科学家Yann LeCun;

(BlenderBot3聊天记录 图源:新智元)
再例如竹间智能开发的小影机器人,能够自主学习并记住用户的喜好和习惯,在回复正常任务型对话时,能更“体贴”一些——例如“这首歌能驱散内心的忧伤,小影会一直陪伴在你身边”、“是不是经常出差的节奏”······
这类助理目前在汽车领域应用较广,例如微软小北、HiPhiGo,HUAWEI HiCar等等。北汽集团与小冰在北汽智能座驾BEIJING-X7上推出主动式虚拟副驾小北,在实现全车级的语音控制之外,可以与乘客进行自然而富有情感的互动。
还有一种是投身心理健康的治愈系“心理治疗师”——例如Vivibot、Emohaa。
“对于可能正在经历悲伤或抑郁情绪或焦虑的人来说,这些聊天机器人是恢复心理健康的重要第一步。”Vivibot的创始人Danielle Ramo表明了投身这一领域的初心。
Vivibot正通过回答患者问题并定期与他们互动,帮助患有癌症或其家庭成员正在接受癌症治疗的年轻人缓解心理压力。
2021年面世的Emohaa,运用共情提问、自我暴露、积极关注等心理咨询师常用策略,对用户不同层级的需求予以满足,包括但不限于缓解坏情绪、陪伴、给予建议等等。
(Emohaa聊天记录 图源:Emohaa微信公众号)
有研究显示,这样的机器人能够帮助用户消除顾虑,让他们更容易打开心扉——美国南加州大学的创新技术研究所 Morency 博士曾进行一项对比,发现“当人们认为电脑的背后没有人的时候,他们更愿意表现出悲伤”。
目前,国内玩家逐步切入 toG、toB 行业场景小试牛刀,比如军队/武警/消防官兵等特殊职业、精神卫生医生群体的辅助需求、社区居民和社工群体、大型企事业单位等,包括但不限于:
在近两年的西安、上海抗疫中,Emohaa为大学生、志愿者们开放24h心理咨询服务(包括部分时段的人工心理支持),累计服务上万人次,用户满意度超90%;
今年3月,深圳市福田推出的“抗疫心理健康服务” 借助镜象科技的 AI 心理技术,通过“AI+心理”智能模式 7*24 小时响应心理倾诉需求。
提及商业变现问题时,业内人士表示:“要慢慢来”。Emohaa创始人黄民烈表示:“希望未来的投资人能有社会情怀和前瞻性,能够认可AI+精神心理的赛道,愿意和公司一起耕耘,不急于短期变现。”
在各路情感机器人变现的道路上,玩家们都不着急。相比之下,他们更着急的是:“我的机器人什么时候能够更‘善解人意’?”
03 情根尚浅
“善解人意”对于现阶段的聊天机器人来说,还较为吃力,在搞懂“是什么”的问题上,还存在着较大挑战:
在《2021年中国智能客服满意度调查报告》中显示,仅有9.6%的用户认为,智能客服问题解决能力高于人工客服。回答千篇一律(59.1%)、重复循环操作(50.6%)、答非所问(47.3%)等是用户智能客服使用中遇到的主要问题。
也就是说,在底层技术上面,各家都要多下功夫。
在算力取决于硬件、算法基本开源的情况下,数据成为大施拳脚的地方,也是各家研究机构和企业角力的核心。
但在搜集数据的过程中,困难重重。
首先要提及的便是数据标注环节。这是因为,有了标注数据,算法才能在基础上进行训练,数据标注的质量越高,学习结果越精确,NLP迈入实用阶段的可能性越大。
但很多企业在这个环节脑袋都大了——太费事了。
一是数据标注需要专业的人去做。据Emohaa背后团队透露,他们很多的标注工作都是心理专业的学生、实习心理咨询师、执业心理咨询师,和专业的心理咨询机构合作,如此导致标注成本很昂贵。
二是一些领域的类别体系太过细致和复杂,AI很可能学不会。
在心理咨询中情绪可以细分为32个类别,哪怕是聘请心理专业人士去标注,标签太细也很难区分,不同人有不同的理解,又会让数据标注存在一致性问题。所以团队目前也只能从10类情绪的标签体系做起。
其次是在评价环节,也不是谁都可以反馈。
评价环节一般是算法自动评价和人工评价。算法自动评价主要通过让AI做一些测试题并评分,成本可以忽略不计,但是人工评价就比较贵——例如黄民烈团队表示,要找很多匹配的用户跟它聊天,然后根据交互情况,对结果进行打分。这就需要大量的、特殊的、易于沟通的群体,必将耗时耗力耗钱。
而目前的产品形态大多都是多模态模型,无疑又增加了难度。
由于多模态数据蕴含的信息更为复杂、模态间对齐较为困难等问题,导致多模态的数据标注难度更大——人类较为复杂,文字、表情、语气等信息很有可能表达的不是一个意思,机器人崩溃的概率很大。
在这样的难度下,各家都表示,先培养信任,积累数据。
前微软(亚洲)互联网工程院副院长李笛表示,小冰一开始的目的就是为了积累数据——没有做一个 APP 让用户来下载,而是在各个地方刷存在感,如微博、微信等用户密集阵地。
也是为了培养信任——人们会因为在某一件事情信任一个人之后,很有可能各方面都信任他。当各方面都信任这个 AI 的情况下,它有一天给用户推荐一件事情,用户很有可能会去试试。
数据的积累、信任的培养,是为了背后的框架
李笛表示,小冰能够把数据和训练成果反馈给框架,从而推进框架的技术发展。不是从流量中收钱。而是把框架里的技术拿出来去解决一些垂直领域的问题,例如在奥运赛场上,小冰和冬奥会合作的高空自由滑雪项目裁判,是团队从框架里面积累出来的计算机视觉技术。
而AI大户百度,也希望通过两位情感机器人与用户间的对话,得到用户对AI回答准确度的反馈(每一句话都有赞同和不赞同的标识),从而优化模型,为背后的框架注入新鲜的血液。
而这,先得花大量的营销费用+差异化的人设,让大家频繁地和“叶悠悠”、“林开开”聊天,并且乐于给出自己的反馈。
评论