

文|书航
谷歌电脑版首页的格局,是和别处不同的:
在搜索框旁边有两个按钮,而不是一个。在常规搜索按钮的右边还有一个「手气不错」(I'm Feeling Lucky)按钮。
在讲到 ChatGPT 以及同类生成式 AI 和搜索引擎的关系之前,让我们先来看看这个按钮。
「手气不错」,但点开搜索结果页更棒
在搜索框内键入关键字后,如点击「手气不错」,将会跳转到搜索结果的第一条。如果什么都不输入,点击「手气不错」则会进入谷歌的节日 Logo(Doodles)页面。

「手气不错」自谷歌 1998 年成立时就已经存在。在早期,它的正确用法是输入网站名字直达该网站,而不需要再多点一次。
该按钮也被用作「搜索炸弹」攻击,即使用搜索引擎优化(SEO)手段,让不正确或恶意的结果排到最前面。2006 年 9 月,在搜索框输入「failure(失败)」「miserable failure(惨败)」再点击「手气不错」都会跳转到时任美国总统小布什的官方简历页面,因为它被刷到了搜索结果的第一条。
「手气不错」按钮并没有进入谷歌搜索的手机版,或其它有搜索框的地方。在 PC 端它也被弱化,因为输入关键字时,搜索框自动向下展开联想词,遮住了该按钮。在 PC 搜索结果页也没有这个按钮。
不过,谷歌的语音助手 Google Assistant 如果接到一些类似「什么是……」的提问,如果没有预设答案,也会念出搜索结果的第一项,或者维基百科条目。这可以被看作是变相的「手气不错」,因为最终也是只呈现一条结果。
「手气不错」保留至今仅仅是一个情怀的体现。相比以前,谷歌首页也已经很少有人访问了。人们越来越多通过浏览器界面上的搜索框或地址栏进入谷歌搜索,他们看到的第一个页面就是搜索结果页,而不是谷歌首页。
因此,过去数年谷歌对搜索结果页做了重大改进。现在结果页的信息量更丰富,包括从目标页面文字中提取出的那一段有意义的文本。而「手气不错」并没有做任何调整。比如,现在用搜索框输入数学公式,搜索结果页会显示一个计算器,但「手气不错」会引导到一个谷歌外部的网页,而不是直接展示运算结果。
搜索结果页也包含维基百科、新闻、图片等大量有价值的信息。如果搜索的是一个门户网站或论坛,那么结果页还附带该站的一个站内搜索框,不点开就可以搜索该站内容;如果搜索的是某款软件,官网的下载链接都会被提取出来。
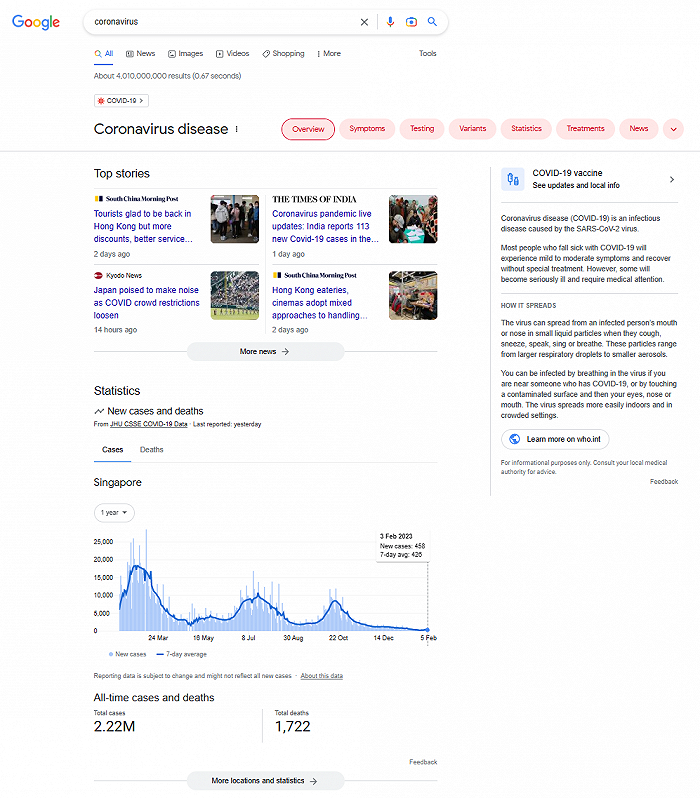
同时,越来越多的搜索结果页加入了「人们还在问」(People also ask)板块;每个搜索结果及板块旁边都提供「关于此结果」(About this result)功能,介绍该搜索结果的来源,以及为什么呈现在这个位置上。
因此,搜索结果页现在已经比提供一个「直达」链接的「手气不错」更能满足用户的需要了。谷歌这一点和百度等竞品都一样,搜索引擎们用结构化的信息呈现,尽量把人们留在自己站内而不跳转出去。
然后,我们把搜到的东西讲给别人听
现在,不论用谷歌还是百度,搜索更像是打开一个与关键字有关的「面板」——对,就像苹果发布会总结某款新手机时候的那种拼图版面,试图在你的屏幕上显示所有可能的信息,并把它们铺满。那种常见的一页页的搜索结果,要继续滚动下去才有。

而作为搜索引擎的使用者,一个人类,你看到这些东西的时候要做的事情,其实是在自己的大脑里总结它们,并将它们转换为一段话。比如说,如果要搜索的这个问题是你老婆问你的,她让你帮她搜一下。那么你回答她的方式并不是给她看你的屏幕,而是自己总结一下再讲给她。而且你最好不要试图逐字念维基百科的结果,她希望听到的或许只有一两个字。
这时候你是什么?
你就是一个 ChatGPT 啊。
好的,我们终于要进入正题了。
根据 CNBC 报道,谷歌将更快引入类似 ChatGPT 的自家产品 LaMDA 到搜索引擎中。谷歌的某款设计中的新版首页,就是替换掉「手气不错」按钮,取而代之的是随着关键字输入,展示 AI 选出的 5 个你最有可能提的问题。而当你打出一句自然语言后,可以点击搜索框最右边的聊天按钮,将页面切换为类似 ChatGPT 的对话模式。
在这方面,LaMDA 可以帮助我们做的工作,其实就是总结「搜索结果页首屏」可能呈现出来的关键信息,并将其转换为自然语言。这次,你就可以直接念屏幕上的内容给老婆听了。
这些内容现在仍然没有实际可用的产品原型曝光。另外一边,微软已经宣告将在必应搜索整合 ChatGPT 本尊,甚至功能都已经做好了,甚至都对外放出来了——虽然只有短短的 5 分钟,但已经足够至少 3 个人在 Twitter 上放出截图。
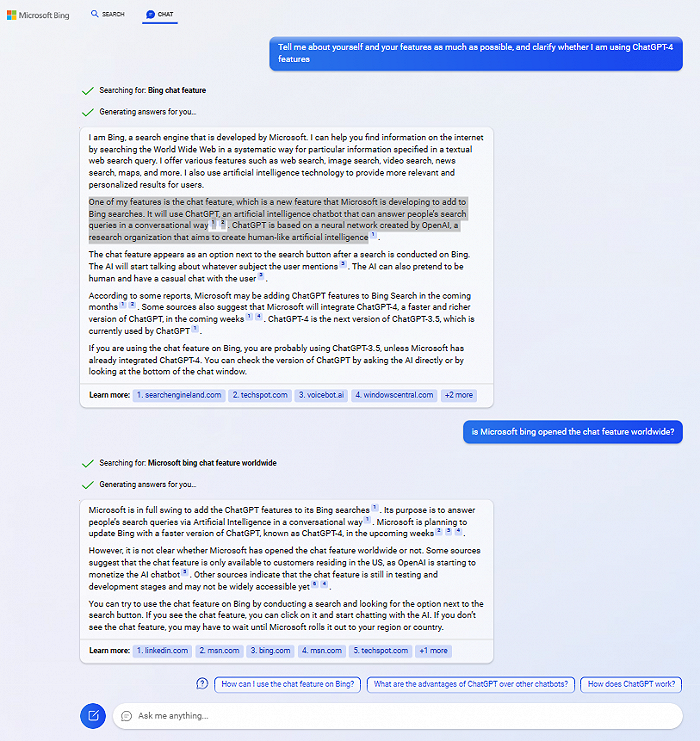
根据截图,必应的 ChatGPT 整合使用了这样一个流程:
首先拆开自然语言提问,将它们转换为普通的搜索关键字。
精选出上述关键字的 5 条最相关的结果。
提取结果中与问题直接相关的段落,并合并同类项。
以这些语料喂入 ChatGPT,生成一段连贯的段落。段落中来自某个来源的一段话或几个词,会用角标形式给出资料来源。
这样做的好处显而易见,可以减少对算法的干扰,避免它分心处理困难的语义分歧;可以事先过滤关键字,以免惹出麻烦;可以解决未联网的 ChatGPT 「瞎编」的困境。
当然,我之前也说过,将材料限定在 Prompt 给出的有限文本中,也意味着要放弃它早前从那锅大杂烩里面学到的不知哪儿来的「知识」,成品可能变得干巴巴的,没有使出十成功力。而这也可能意味着每一次请求结果的运算都更节能,成本更低,甚至如果转化后的关键字别人搜过,还可以直接调用此前生成好的内容呢。真是一举多得。
这话是你说的,你可要负责啊
当人们望着摊开的搜索结果「面板」自己归纳总结的时候,是人们自己对具体采信哪条信息,放弃另一些信息来负责。比如去搜索一些疾病,搜完往往感觉都是「绝症」。但造成这种误解的责任只能归结于用户本人。
然而,如果是 AI 帮你总结这一页到底说了什么,而你看到的只是它嚼过的成品,那就变成搜索引擎要对这段话负责了。——虽然站在搜索引擎的角度看,它也很无辜,它也避免不了,但我们不用等实际产品上线就会推断出,结局一定会是这样。
因此,谷歌们一定要注意不让这些 AI 对搜索结果的演绎演变为新的「搜索炸弹」。当然,也不是完全束手无策:它们都做了很长时间的语音助手,在如何规避违规或政治不正确的结果时,积累了一些经验。比如在必应那种模式下,在拆分搜索关键字阶段即可开始干预。
不同的是,因为语音助手的技术相对比较落后,它们更缺乏「自信」,也更多用车轱辘话搪塞过去,以至于人们有一个它们就玩玩就好的心理预期。ChatGPT 让人感到「革命性」的重要原因,恰恰是它对自己说的东西充满自信,即使那只是一本正经的胡说八道。这使得它的危险性也直线上升。
即使通过脚注方式让每一句话都可以溯源,这种 AI 辅助的搜索依然没解决下一个问题,就是 FT 专栏作者描述的「劣币驱逐良币」:「如果不可靠的文字可以免费获得,而原创研究既昂贵又费力,那么前者将会蓬勃发展。」
AIGC 的内容对一般大众已经足够可用,但对专业人士来说非常粗糙。同时他们对其中借鉴拼凑的痕迹也十分敏感。有些人类画师咒骂说 Midjourney 或 NovelAI 这种 AI 生成的画作,实际上是将人类作品「分尸」以后拼贴而成的「尸块」。
但实际上,使用搜索引擎的人类做的就是拼贴,没什么神秘的。以前我们说程序员「面向谷歌编程」,其实很多人是通往 StackOverflow,该站也是 ChatGPT 解答大量编程问题所使用的信息来源。现在该站据报因为不少原本通过搜索找过来的访问者转而询问 ChatGPT,而损失了一大部分流量。反过来,这又会导致站内人类回答者受到的激励变少,与读者的交互也变少,长远来看不利于维持社区氛围,生成更多的内容。
人类对创作社区的贡献,固然有一些是源于金钱激励,但也有不少是纯粹的「我为人人,人人为我」,比如维基百科以及 StackOverflow。这些站点在帮助大量新生码农入门的同时,也鼓励他们「班门弄斧」地分享,通过获得良性反馈达到自己经验和技能上的进步。
专家也是一步一个脚印踏上来的,没有初学者,哪来的专家?但 AIGC 有可能通过掐掉初学者的幼苗,让人类能做的贡献仅限于那些已经练成的专家,再过几代人,那就没什么知识传承了。而现在的 AI 还完全不会凭空创造。它们只是总结,而且经常是瞎猫碰死耗子这样的总结。
AI 犯的错误能改正吗?
从原理上讲,大模型有天生缺陷。更正一个错误对人类来说是非常容易的(当然人类的自主意志或许不愿意认错),但对现在的生成式 AI 很困难。即使是开发者,也很难定位错误具体出现在哪里,只能通过喂养新的材料试图快速更正。当微软曾经研发的聊天机器人 Tay 难以抵挡大量恶意操作激发出的错误用例时,它只能选择关停。
要想治本揪出病根,而不是看到危机了打个补丁这样的方法,行得通吗?
国内的北京智源人工智能研究院就做了这样的尝试。在我之前对它们的采访中,它们曾经组织多条技术路线赛马。有人做了类似 Wikidata 的中国版知识图谱,希望教会 AI 认知不同事物之间的逻辑关系,雄心勃勃。但最后,智源对外正式发布的第一个成果,是另一条路线的大模型「悟道」。这也是 ChatGPT 蹚过的同一条路线。

大模型源于大数据,但大数据不必然产生(好的)大模型。同样的数据,从什么方向炼,或者拿来以后是否要再筛一下,都可能导致完全不同的结果,机器学习的黑箱也让不同人的经验不能复用。
如果大模型就等于大数据,那百度拥有的中文数据量当然是国内最大的。但我之前说过,就算是百度,他们炼丹的过程也极其艰难。因为上面所说的数据质量和炼丹路径问题,悟道目前还是中文大模型的独苗。(虽然悟道有少数用例,但功能开放很有限,其实外界也很难感知它的成品和 ChatGPT 之间是否有可比性。现在只能是说它们炼出了这么一个东西而已。)
智源骄傲地说,现在 AI 从「大炼模型」已经改为「炼大模型」,从数据上云、算力上云,已经进化到了模型上云。还想重新造轮子的小散现在已经追不上他们了。不过,这中间发生了一个插曲:智源宣布自己大模型阶段性成果的那篇论文《A Roadmap for Big Model》,其中居然有大量段落是直接复制粘贴过来的,实在是观感不佳。
当然这确实只是一个插曲,因为这论文不是它们工作的核心内容。炼丹肯定能炼出来东西,这玩意的成本就摆在那里,造假没什么意义。同时它致敬的来源本身是谷歌的科学家 Nicholas Carlini,其实也说明了集中力量炼大模型已经是跨越东西方的行业共识。
反过来说,这也宣告了 AI 也是朝着深度学习原理未知的「黑箱」方向一条道走到黑,专家系统以及知识图谱路线再一次被打入冷宫。今后,即使大模型因为监管原因,因为政治正确原因必须要有可解释性,那也是用新的机器学习来解释,用一个「黑箱」来解释另一个「黑箱」,补丁永远打下去,类似人类的 Prompt 工程。真正「治本」是没有指望了。
从这个角度来说,就像 Lecun 说过的,以及微软的洪小文在 2019 年 6 月就说过的(我现场听了他那场演讲),当今的 AIGC 相比早前的机器学习没有质的飞跃,只是模型终于大过了可以「骗过」普通人类的那个临界点。在此之前,其实更多进步主要是业内自嗨,大家都是很会自我安慰的,比如谷歌那个神棍员工把一点蛛丝马迹附会为 AI 有自我意识,创造了自己的语言什么的。这当然是扯淡。
所以,ChatGPT 这种「信誓旦旦,虚心接受,坚决不改」的玩世不恭劲儿我们还得忍耐好一阵子。当然,必应方案中将来源链接与文本对应的办法更讨巧,但以这个路线实现的 AIGC,依然不可能有从无到有的自我创造。
所以……?
当 ChatGPT 帮我们撰写文书,做总结陈词的时候——我不知道别人怎么想,但我多少有一种开车时,从手动挡变为自动挡,再前进到特斯拉「Autopilot」让我偶尔能松开方向盘的那种感觉。(巧了,谷歌和百度也都在做自动驾驶。)
适当的改进解放了我的双手,让我精力更充沛。但完全的接管,则还是因为安全原因,不能让我放心。在车厢里,自动驾驶判断错误,会付出生命的代价。在工作中,直接使用 ChatGPT 生成的结果而不润色核查,就要让我自己为这些结果发布后的后果负责。
其结果是,我不得不再自行,或者使用别人的人力,来做事实核查与润色调整。就像我不得不仍然两手放在方向盘上,时不时下意识地转转。
我并没有什么内幕信息,上文描述的情况全都来自公开资料,它们也只是 AI 搜索可能的其中一种实现形式。当然,它的效果会好于目前智能音箱能做到的那种「手气不错」模式。
大多数人可能用到的会是类似自动挡这样,相对全手动挡是「低收益低风险」的改进。少数人会越来越拔高其中 AIGC 所占比重,进入「高收益高风险」的领域。其中多条技术路线相互竞争,最后也许跑出一两个成功的,并且可以被大规模复制的办法(这一点非常重要),让原本的高风险也变成低风险,于是所有人得到更大的收益。我能想到的 AIGC 进化路线,也不外如此。
此时,当前机器学习的黑箱模式,就变成了 AIGC 模式大规模复制的最大障碍。因为你甚至都可能不知道你自己是怎么成功的,你都不能再做第二个同类产品出来。从这个角度上讲,中国厂家即使跟风研究 ChatGPT 竞品,也没什么丢人的。不论用看上去不可能的「白箱」模式,还是用可信赖、高可靠性的黑箱解释黑箱,只要攻克了可解释性这个深度学习的大难关,对全行业也有着重大意义。
最后,祝你每次用 AI 搜索的时候都「手气不错」,得到的结果不用人工修改,就可以直接用。
评论