

文|智东西 ZeR0
编辑|漠影
智东西3月15日报道,最近几天,大模型和生成式AI领域可谓是群英荟萃,进展连连。上周,国内首个可供体验的类ChatGPT模型海豚AI助手上线,邀请公众参与测试。本周又有多项重要进展令人应接不暇。
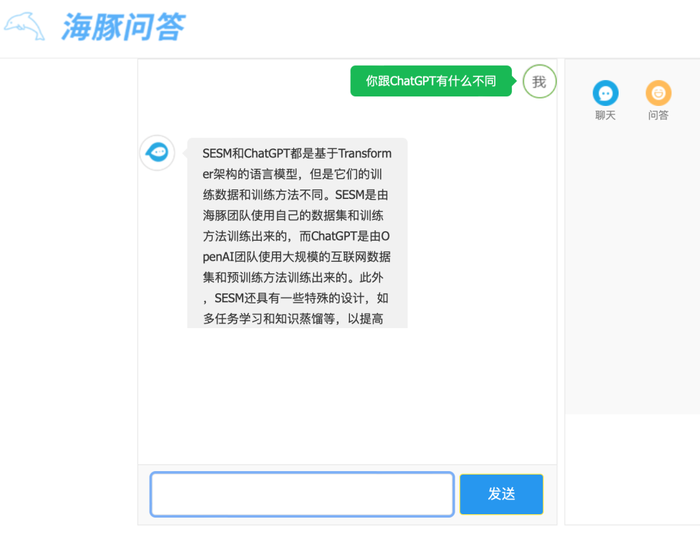
本周二,由清华技术成果转化的公司智谱AI推出了基于千亿基座模型的ChatGLM,初具问答和对话功能,现已开启邀请制内测,并将逐步扩大内测范围。(内测申请网址:chatglm.cn)
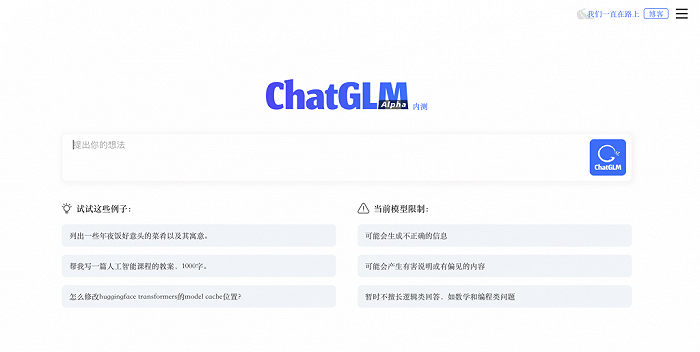
同期,智谱AI还开源了GLM系列模型的中英双语对话模型ChatGLM-6B,支持在单张消费级显卡上进行推理使用。
Georgi Gerganov最近也做了个能在苹果M1/M2芯片上跑Meta开源大型语言模型LLaMA的项目llama.cpp。此前Meta声称LLaMA-13B在大多数基准测试中的表现优于GPT-3(175B)。
斯坦福大学亦于周二发布了一个由LLaMA微调的全新开源模型Alpaca,训练3小时,性能媲美GPT-3.5,而训练成本不到600美元。其中在8个80GB A100上训练了3个小时成本不到100美元,生成数据使用OpenAI API的成本不到500美元。

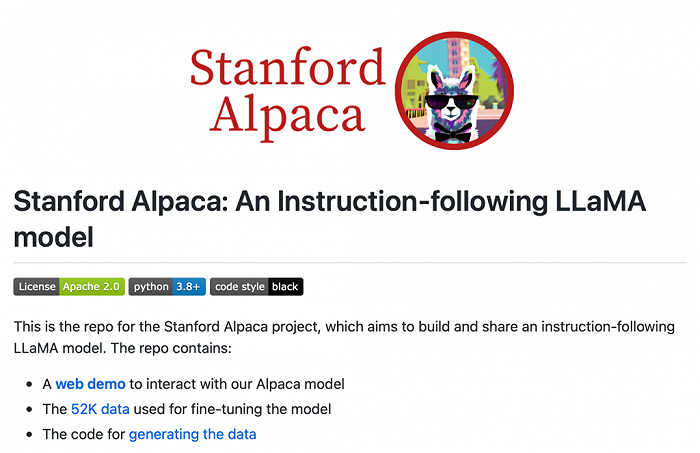
这两个项目都得到了图灵奖得主、深度学习三巨头之一、Meta首席AI科学家杨立昆(Yann LeCun)的转发支持。
同日,谷歌宣布开放大型语言模型PaLM的API,帮助企业“从简单的自然语言提示中生成文本、图像、代码、视频、音频等”。谷歌还推出了一款与PaLM API搭配使用的新应用MakerSuite,用户可以用它迭代提示、使用合成数据扩充数据集、轻松调整自定义模型。
大模型及生成式AI的研发与应用,正肉眼可见地热闹起来。
01 类ChatGPT产品海豚AI助手上线公开可体验
上周,海豚团队宣布已成功开发了国内首个可供体验的类ChatGPT模型,并将其发布到了公开平台,欢迎公众参与测试。
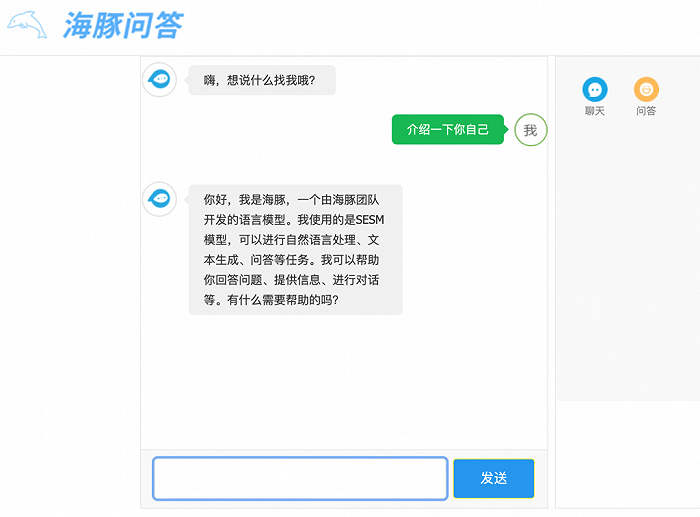
海豚团队介绍道,海豚AI助手是一款类似于ChatGPT大语言模型的AI产品,具有帮助用户获取知识、高效写作、辅助决策的功能。智东西分别对三项功能进行了体验。
获取知识方面,海豚会根据用户的提问,自动搜索相关文献并提供详细的解释和解答,相比传统搜索引擎更加快捷和准确。海豚还支持对于一些特定领域的深度探索,比如医疗、法律、金融等。比如你可以问它疾病的症状、法律条文的解释、金融产品的分析等等。

高效写作方面,海豚能够自动生成文本,帮助用户撰写作文、论文、邮件、演讲稿等,并能够为用户提供写作建议和优化方案,还可以为用户提供各种写作模板和格式化工具。

辅助决策方面,海豚可以自动为用户提供相关的数据和分析结果,并为用户提供决策建议和优化方案;还可以为用户提供各种决策模型和工具。下图是海豚AI助手针对“6岁小孩怎么学习计算机编程”问题给出的回答。

据介绍,海豚团队拥有自主研发的NLP大模型,对话机器人等核心技术,并通过软硬结合的方式,将AI助手融入到“手机”、“机器人”、“车载”、“家居”四大场景中,为用户提供日常生活所需的全方位服务。
其团队成员主要由毕业于清华大学、南京大学、加州大学伯克利分校、香港中文大学等知名高校,以及工作于IBM、腾讯、华为等国内外IT公司的资深员工组成。
02 千亿参数对话模型启动内测:多轮聊天流畅,能写稿能编程
由清华大学计算机系技术成果转化而来的公司智谱AI,现已开启ChatGLM线上模型的内测。用户需要使用邀请码进行注册,也可以填写基本信息申请内测。
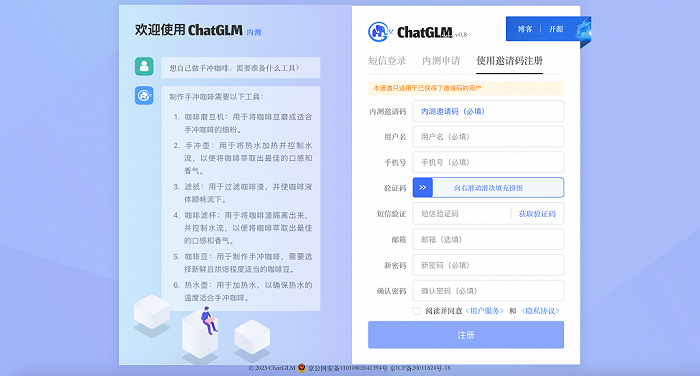
智东西也对ChatGLM的多轮对话、内容生成、辅助编程等能力进行体验。
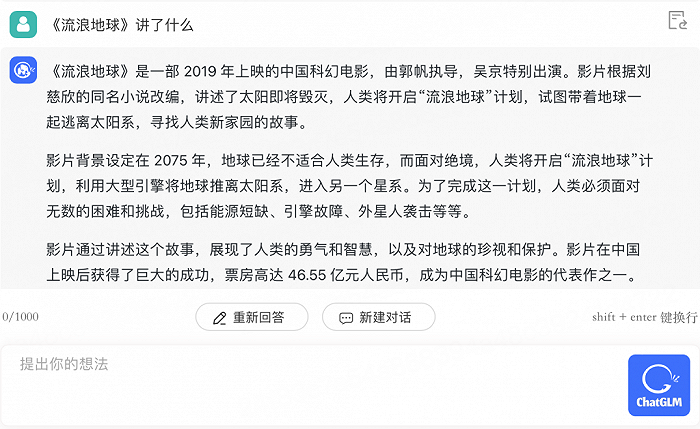
问它《流浪地球》讲了什么,回答基本无误。
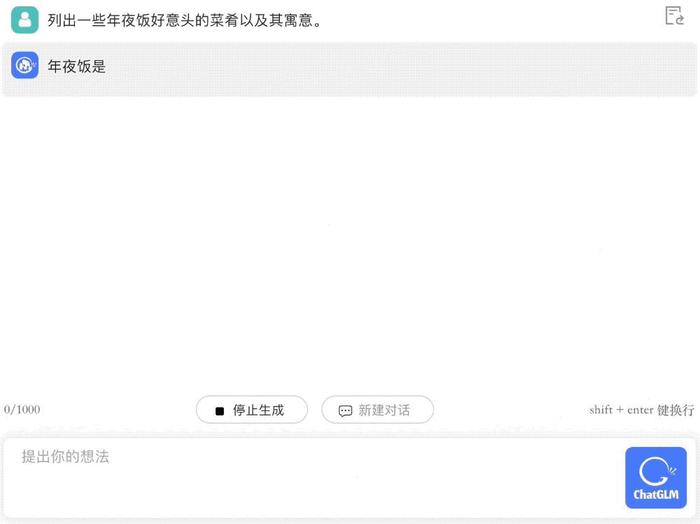
在提供建议上,它也是个合格的助手。
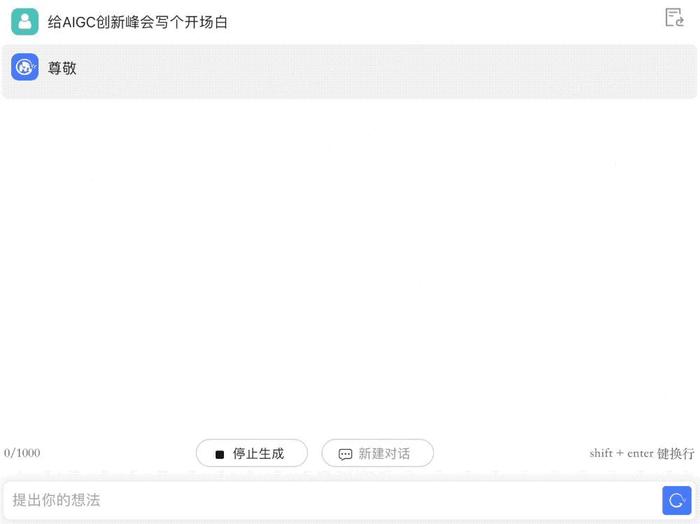
让它给AIGC创新峰会写个开场白,成文速度飞快,指出错误后能迅速修改。
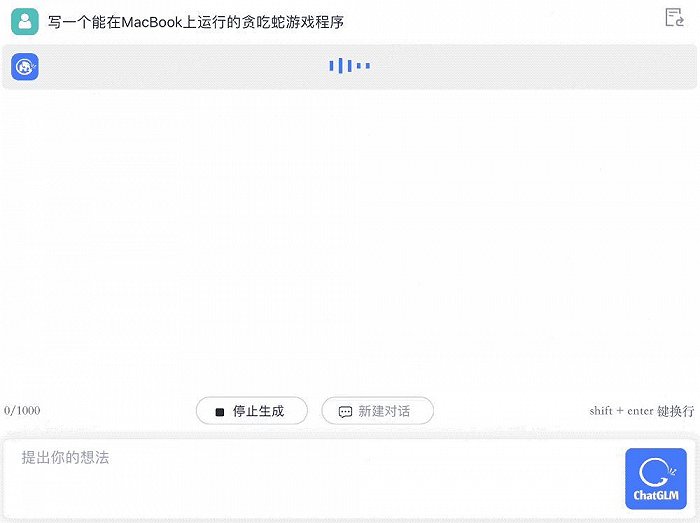
写一个能在MacBook上跑的贪吃蛇游戏程序也不在话下:
ChatGLM线上模型的能力提升主要来源于独特的千亿基座模型GLM-130B。它采用了不同于BERT、GPT-3以及T5的GLM架构,是一个包含多目标函数的自回归预训练模型。
智谱AI致力于打造新一代认知智能通用模型,提出了Model as a Service(MaaS)的市场理念,于2021年合作研发了双语千亿级超大规模预训练模型GLM-130B,主导构建了高精度通用知识图谱,把两者有机融合为数据与知识双轮驱动的认知引擎,并基于此千亿基座模型打造ChatGLM。
2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B是亚洲唯一入选的大模型。在与OpenAI、Google Brain、微软、英伟达、Meta AI的各大模型对比中,评测报告显示GLM-130B在准确性和恶意性指标上与GPT-3 175B(davinci)接近或持平。
GLM团队在博客文章中坦言,ChatGLM距离国际顶尖大模型研究和产品还有一定差距,他们将持续研发并开源更新版本的ChatGLM和相关模型。
智谱AI也推出了认知大模型平台Bigmodel.ai,形成AIGC产品矩阵,包括高效率代码模型CodeGeeX、高精度文图生成模型CogView等,提供智能API服务。
03 62亿参数对话模型已开源支持单卡推理
除了开启ChatGLM内测外,智谱AI还将支持中英双语问答的对话语言模型ChatGLM-6B开源,并针对中文进行了优化。
该模型基于General Language Model(GLM)架构,具有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。
ChatGLM-6B使用了和ChatGLM相同的技术,针对中文问答和对话进行了优化,具备较好的对话与问答能力。以下是其对话效果的一些示例:
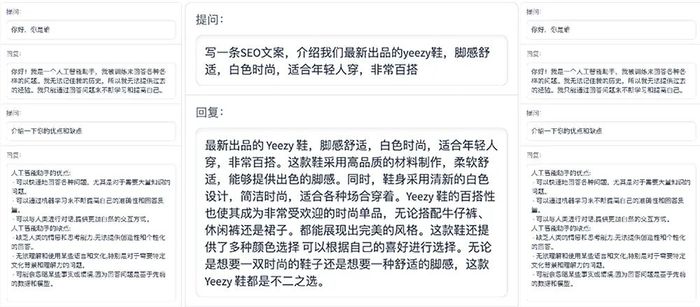
经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。
具体来说,ChatGLM-6B具备以下特点:
(1)充分的中英双语预训练:在1:1比例的中英语料上训练了1T的token量,兼具双语能力。
(2)优化的模型架构和大小:吸取GLM-130B训练经验,修正了二维RoPE位置编码实现,使用传统FFN结构。62亿的参数大小,使研究者和个人开发者自己微调和部署ChatGLM-6B成为可能。
(3)较低的部署门槛:FP16半精度下,需要至少13GB的显存进行推理,结合模型量化技术,这一需求可以进一步降低到10GB(INT8)和6GB(INT4),使模型可部署在消费级显卡上。
(4)更长的序列长度:相比GLM-10B(序列长度1024),序列长度达2048,支持更长对话和应用。
(5)人类意图对齐训练:使用监督微调、反馈自助、人类反馈强化学习等方式,使模型初具理解人类指令意图的能力。输出格式为markdown,方便展示。
不过由于ChatGLM-6B模型的容量较小,不可避免的存在一些局限和不足,包括:
(1)相对较弱的模型记忆和语言能力:在面对事实性知识任务时,可能会生成不正确的信息,也不太擅长逻辑类问题(如数学、编程)的解答。
(2)可能会产生有害说明或有偏见的内容:ChatGLM-6B只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
(3)较弱的多轮对话能力:上下文理解能力还不够充分,在面对长答案生成和多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
感兴趣的开发者可以下载ChatGLM-6B,基于它进行研究和(非商用)应用开发。GLM团队希望能和开源社区研究者和开发者一起,推动大模型研究和应用在中国的发展。
04 在苹果M1/M2芯片上跑LLaMA
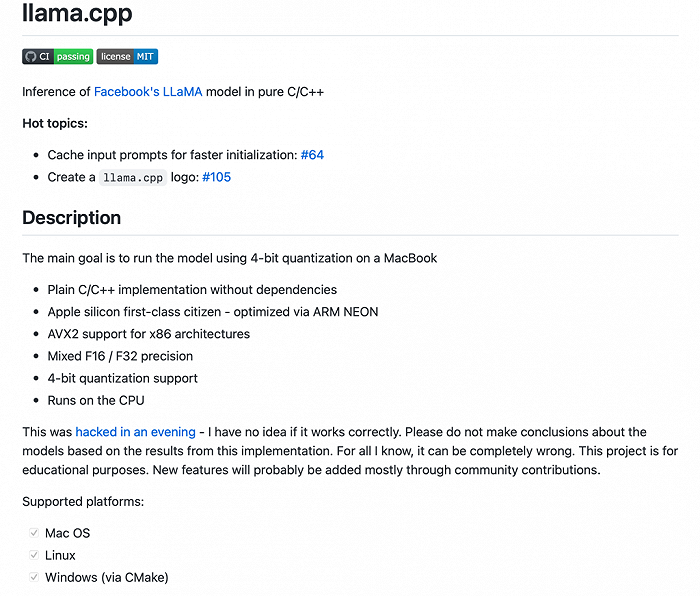
Georgi Gerganov近日公布了一个没有专用GPU也能跑Meta大模型LLaMA的项目llama.cpp。
在基于苹果M1芯片的Mac上运行LLaMA涉及多个步骤,感兴趣的朋友可以参见教程( https://dev.l1x.be/posts/2023/03/12/using-llama-with-m1-mac/)。
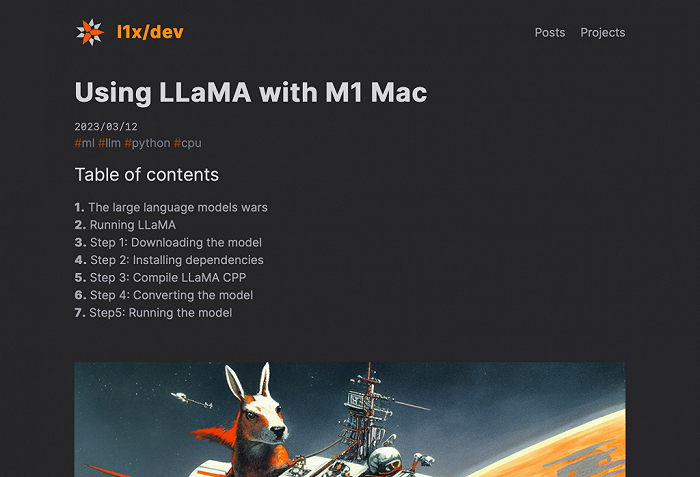
在基于M1/M2芯片的64GB MacBook Pro上跑拥有70亿参数和130亿参数的LLaMA大模型可参见(https://til.simonwillison.net/llms/llama-7b-m2)。

如图所示,在M1/M2 MacBook电脑上跑LLaMA 70B大模型,输入提示词“登月第一个人是”,得到上述结果,从阿姆斯特朗登月的年龄、中间名和日期来看,没有出现明显的事实性错误。
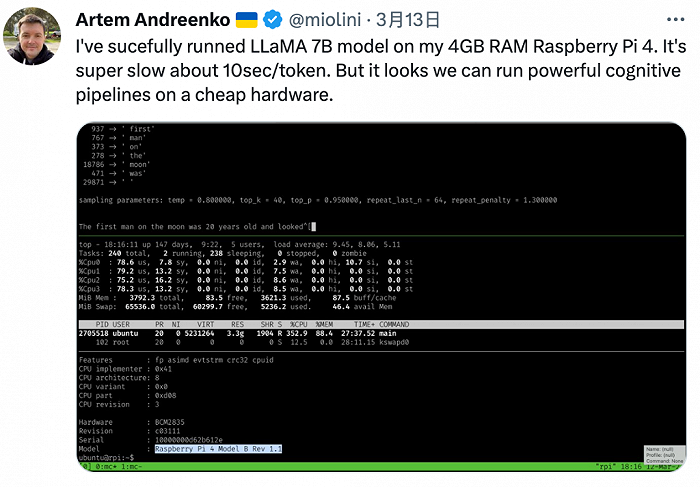
研发人员Artem Andreenko说,他已在4GB RAM Raspberry Pi 4上成功运行LLaMA 7B 模型。尽管速度很慢,大约10秒/token,但这展现了在便宜的硬件上运行强大认知pipelines的可能。
05 斯坦福开源模型Alpaca:性能媲美GPT-3.5,成本不到600美元
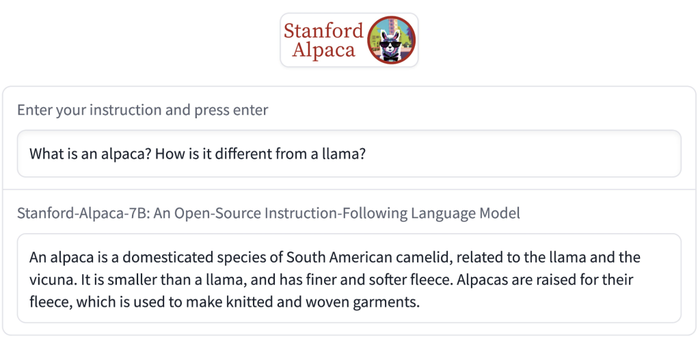
斯坦福大学在本周二发布了一个由LLaMA微调的全新开源指令跟随模型Alpaca,仅供研究使用,禁止用于任何商业用途。
该模型通过在52k生成指令上对LLaMA 7B进行微调实现,性能表现得像OpenAI GPT-3.5(text-davinci-003),而训练成本不到600美元,因此便于复制及广泛部署。
该团队的目标是构建一个简单的模型/训练程序,让学者们可以用有限的资源进行研究和改进。
具体而言,Alpaca模型使用来自LLaMA 7B模型的监督学习进行了微调,基于来自OpenAI text-davinci-003的52K指令跟随示例。

该团队从自生成指令种子集中的175个人工编写的指令-输出对开始,然后提示text-davinci-003使用种子集作为上下文示例生成更多的指令,通过简化生成pipeline来改进自生成指令方法,并显著降低了成本。
其数据生成过程产生了52K独特指令和相应的输出,使用OpenAI API的成本不到500美元。
在配备了这个指令跟随数据集之后,该研究团队使用Hugging Face的训练框架,利用完全分片数据并行和混合精度训练等技术,对LLaMA模型进行了微调。在8个80GB A100上对7B LLaMA模型进行微调需要3个小时,这在大多数云计算供应商上花费的成本不到100美元。
Alpaca团队正在发布其训练配方和数据,并打算后续发布模型权重。
06 谷歌开放PaLM API 推出生成式AI新平台
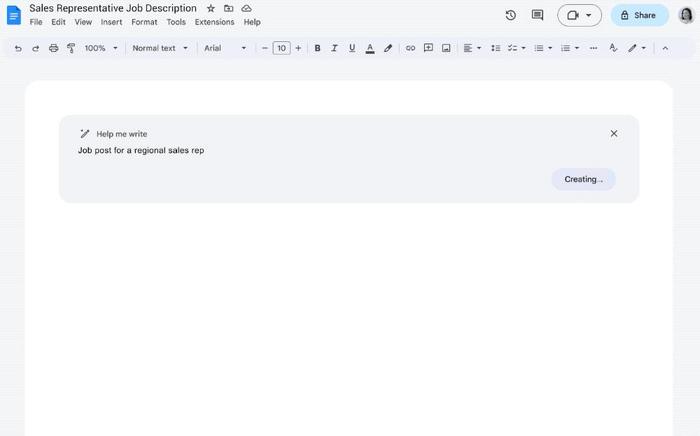
本周二,谷歌宣布开放大型语言模型PaLM API,帮助企业“从简单的自然语言提示中生成文本、图像、代码、视频、音频等”。下图是生成式AI在谷歌文档中帮助撰写职位描述的示例。
谷歌还推出了一款与PaLM API搭配使用的新应用MakerSuite,用户可以用它迭代提示、使用合成数据扩充数据集、轻松调整自定义模型。
计算密集型的训练和部署工作由谷歌云处理。同时,谷歌在其帮助企业训练和部署机器学习模型的Vertex AI平台中扩大对生成式AI的支持,允许用户访问由Google Research及DeepMind构建的更多模型,未来还将能利用开源和第三方系统。
此外,谷歌推出一个生成式AI新平台Generative AI App Builder,允许开发人员快速发布新体验,包括机器人、聊天界面、自定义搜索引擎、数字助理等。开发者可以通过API访问谷歌的基础模型,并可以使用开箱即用的模板在几分钟或几小时内快速启动生成式应用的创建。
07 结语:生成式AI热潮正汹涌而来
毋庸置疑,大模型及生成式AI领域正变得越来越热闹,相关的研发与创意正喷涌而出。
我们既看到科研团队站在开源模型的肩膀上,研发出更廉价易得、能跑在消费级硬件上同时性能媲美GPT-3.5的大模型,又看到谷歌等科技巨头试图将更多AI工具及服务供给企业级用户。
生成式AI时代的大幕已然拉开,尽情享受吧!
评论