
文|极客电影
英伟达再次站到了时代浪潮之上:
被ChatGPT选中的英伟达成功摆脱“矿圈”影响,并且极有可能在未来成为AI领域的核“芯"。
过去三十年间,英伟达制造的芯片几乎主导了整个游戏和计算机图像产业,而人工智能业务的增长为它带来了新的盈利方向。
英伟达创始人黄仁勋在十年前的深谋远虑,让公司得以乘着时代风口“起飞”。
大约在十年前我们就发现,AI这种制作方式可以改变一切。
我们调整了公司方方面面的发展规划,我们生产的每一个芯片都具备人工智能技术。
纵观英伟达的崛起,靠的绝不是运气。
图形处理“霸主”成长史
英伟达的英文名称 NVIDIA 前两个字母 NV=Next Version(下一个版本);
NVIDIA是拉丁语“嫉妒”的意思,他们希望自己产品的计算速度可以快到让所有人都嫉妒,所以选择了代表羡慕嫉妒恨的绿眼睛作为公司标志。

英伟达的LOGO——绿眼睛
英伟达创始人黄仁勋,1963年出生,9岁时移民美国,后进入在俄勒冈州立大学学习电气工程,并在斯坦福获得硕士学位。
上世纪八九十年代,毕业后的黄仁勋曾在AMD和LSI Logic工作。在LSI Logic设计部门工作了两年之后,黄仁勋转岗到了销售部门——这是他自认为“人生最佳”的职业转型,销售经验让他学会了“产品和市场结合才是成功关键”。
之后,黄仁勋结识了Chris Malachowsky和Curtis Priem两位曾经在SUN工作过的技术人员,三个工程师常聚在圣何塞Berryessa立交桥旁的小破店Denny's里喝咖啡,讨论如何加快电子游戏中3D图像的渲染速度。
1993年,三人共同在加州一个小公寓里创立了英伟达公司。
英伟达的三个创始人
1999 年,几经市场失败濒临破产边缘的英伟达,在裁掉大部分员工后,推出了号称是世界上第一款官方GPU——GeForce 256。

这是第一款允许自定义阴影和照明效果的可编程显卡。到 2000 年,英伟达已成为微软第一款Xbox的独家图形引擎供应商。
“微软推出XBOX的时机,恰好是我们投入研究可编程着色器(Programmable shader)的时候,它定义了计算机图形学的底层逻辑。”创始人黄仁勋说。
天时地利人和,英伟达的GPU顺势成为最主流的图形处理芯片。
30年前,硅谷研发图形处理芯片的公司群雄逐鹿,如今几乎只剩英伟达和AMD还活着,首席执行官仍是创始人的公司更是少见。
这就必须提到黄仁勋在2006 年下的大赌注——他们发布了一个名为CUDA(Compute Unified Device Architecture)的软件工具包。
当年CUDA刚问世的时候,华尔街对其市值估值为0美元。“直到2016年,即CUDA问世 10 年后,人们才突然意识到,这是一种截然不同的计算机程序编写方式,”英伟达深度学习研究副总裁Bryan Catanzaro说。

正是他们搭建的CUDA开发者平台以其易用性和通用性,让GPU可以用于通用超级计算,最终推动英伟达迅速扩张为图形处理领域的霸主。
从游戏到“挖矿”,再到ChatGPT
英伟达的GPU一度成为了加密货币领域中的硬通货,游戏显卡价格被炒高,英伟达的股票也曾一度高达319美元。
尽管英伟达为“挖矿”专门设计了一款GPU(NVIDIA CMP hx series),但仍然挡不住“淘金者们”购买游戏显卡。

显卡短缺大概到2022年初结束,同年英伟达发布的40系列GPU (GeForce RTX 4080),定价$1199,远远高于30系列$699的价格,这让游戏玩家大为震撼。
显卡供需恢复正常以后,英伟达在游戏行业的营收下降了46%,股价随之大跌,芯片巨头急需业务调整。
“突然一个听起来不可能的软件发现了你”——OpenAI购买了10000个GPU用于AI计算,此后,英伟达开始正式成为人工智能背后的中坚力量。
被 AI 选中的英伟达
01│AI为什么选择GPU?
英伟达在1996年发布GeForce256时,就率先提出GPU(图形处理器)概念,从此英伟达显卡芯片就等同了GPU。
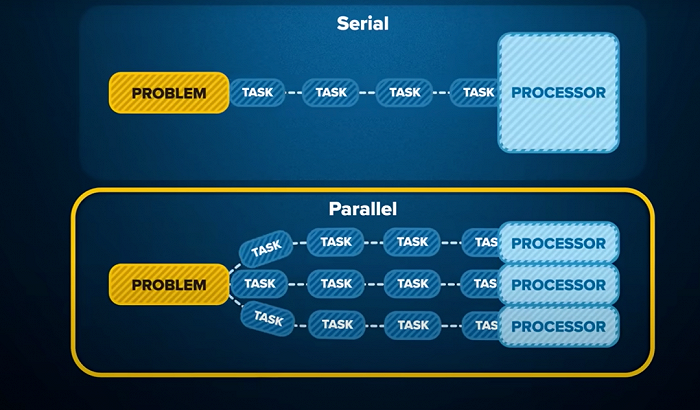
GPU包含成百上千的核心,每个核心处理一个像素点,这样就可以在同一时间内完成对图片中所有像素点的处理。
GPU这种基于大量计算核心的结构,让它特别擅长做那些计算密集且可以大量并行执行的运算,深度学习和AI应用就符合这个特点,而且AI应用里最常见的卷积运算本质是加减乘除这类简单运算。
这也是GPU与中央处理器CPU最大的区别:
CPU适用于需要按时序进行的复杂运算,就像一个渊博的数学教授,什么问题都会,但是雇他的成本很高;
而GPU就像一千个小学生,可同时进行大量简单运算,又便宜又快。
02│GPU 如何推动AI人工智能的发展?
GPU算力提升是AI得以实现的基础,而AI领域的算法进步也让GPU算力提升成为可能。
2009年,斯坦福人工智能研究员推出了ImageNet,这是一个标记图像的集合,用于训练计算机视觉算法;
2012年,被称作“神经网络之父”和“深度学习鼻祖”的多伦多大学教授杰弗里辛顿和他的博士生Alex发表了AlexNet,把在GPU上训练的卷积神经网络与ImageNet数据结合,创造出世界上最好的视觉分类器,一举获得ImageNet LSVRC-2010竞赛的冠军,错误率只有15.3%, 远超第二名的26.2%。
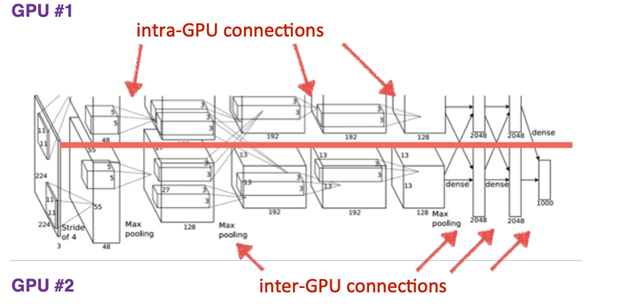
AlexNet原理
同年,英伟达发布了名叫开普勒(Kepler)的GPU架构,从2012年的“开普勒”芯片到2020年的安培(Ampere)架构,GPU的芯片性能在8年里提升了317倍。
英伟达能取得这样成就,主要有两个方面的原因:
首先是半导体制造工艺的进步,这部分功劳当归功于台积电和三星这样的芯片制造商。在芯片架构不变的情况下,单靠工艺的升级,性能也会有好几倍的提升。
另外一个非常重要的原因,就是在英伟达自己在芯片架构上的优化:
首先是张量核心(Tensor Cores)的引入。
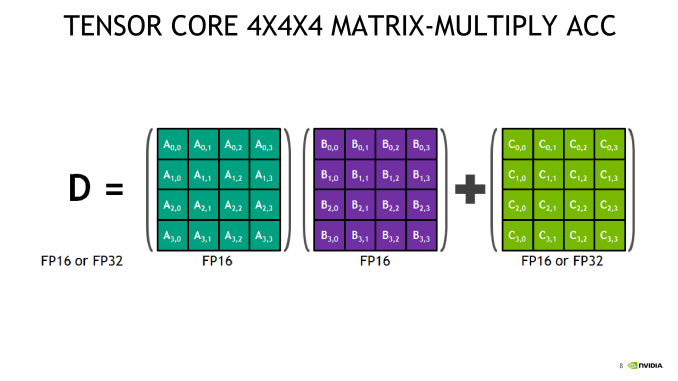

Tensor Cores是一种专为深度学习而设计的计算核心,它执行的是一种特别的矩阵式数学运算方式,非常适用于深度学习训练
2017年12月英伟达发布了首次采用具有Tensor Cores的GPU,专门用于AI领域、特别是计算机深度学习。这就是为什么几乎所有深度学习超级计算机都选择了英伟达的GPU。

英伟达Tensor Cores GPU
其次是,支持更低精度的数据运算。
这是因为研究AI算法的人发现,精度下降造成的准确度下降可忽略不计,因此选择更低的精度能大幅提升算力。
同时,Tensor Cores使人工智能程序员能够使用混合精度来实现更高的吞吐量而不牺牲精度,即针对不同的任务执行不同的精度需求,节约了大量算力。
同样能带来算力提升的,是结构化剪枝(压缩)技术。
剪枝技术是本科毕业于清华大学,现任麻省理工副教授的韩松提出的一种AI模型的压缩技术。他发现在AI模型中,神经元之间的联系有着不同的紧密程度,剪掉一些不那么重要的连接,基本不会影响模型的精度。
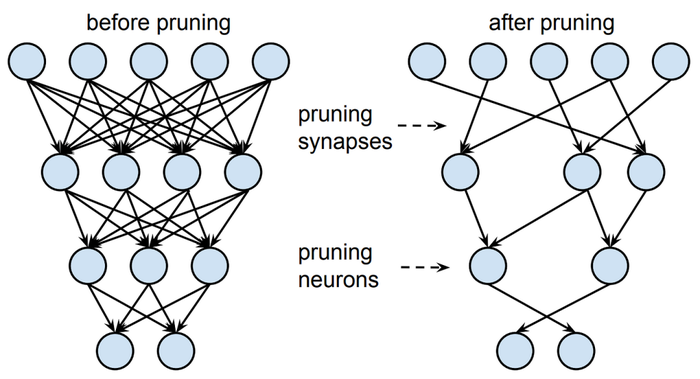
剪枝压缩技术
而近年来神经网络模型里新秀Transformer模型,给算法技术层面带来了大幅进步。
Transformer模型
在NLP领域取得的研究进展都和Transformer息息相关, OpenAI采用的GPT-3模型,就是受到了Transformer模型的启发,参数的数量达到了1750亿个。
然而Transformer模型需要更大的运算量,也就意味着硬件水平得配套。于是英伟达开发了专用于Transformer模型的计算引擎,以适应AI的算力需求。
由此可见,AI算法领域的科研成果和GPU的性能是彼此促进、互相提携的。
巨头入场,图形芯片越来越卷
计算能力就是AI时代的货币。
云计算和互联网大厂纷纷下场做自己的芯片,就是提供更强大的算力,降本增效,来满足不同应用场景的需求。
比如苹果的M1芯片,就是为了让它的产品在视频剪辑等细分场景的应用上有更强表现,而舍弃了通用性。
而英伟达、英特尔设计的芯片更具通用性——芯片设计厂商在通用性和专用性上的取舍,其实体现了他们在商业价值上的自我预期。
2013年,谷歌开始研发用于AI场景的TPU芯片,目的是为了解决公司内部日益庞大运算需求与成本问题。这些芯片几乎只能用于解决矩阵运算,也算是舍弃通用性,追逐专用性的极端了。
甚至连亚马逊都在2013年推出了Nitro1芯片,同样是服务其自身电商业务。
评论