
文 | 产业家 思杭 皮爷
在微软GPT-4遇到诸多问题的最近,谷歌终于向外界展示出了其强劲的实力。
就在昨天,一年一度的Google I/O开发者大会在美国加州山景城的海滨露天剧场拉开帷幕。与往年不同的是,今年的大会主题是近期火爆全球的「AI大模型」,因此格外热闹。
在会上,最重磅的消息是,谷歌推出了最新语言模型——PaLM 2,并作为本次发布会中大部分AI功能的基础模型。
尽管从AI模型整个领域来看,PaLM 2并未取得突破性进展,只是在多语言、推理和翻译功能有所改进,诸如数据隐私和AI“幻觉”等问题依旧存在,但就部分性能而言,PaLM 2已经超过GPT-4。
从各项参数来看,谷歌的大模型已经覆盖到了自身的产品应用,这些产品应用包括文档等办公产品,也更包括和底层云计算的打通,同时还有“个性化AI”概念的提出,这些动作无不在向外界传递出一个信号:谷歌大模型已经可以全面落地,不论在C端还是B端,不论是轻量级部署,还是本地部署。
在过去的一两个月中,中国市场风起云涌,TO B市场的变化更是一日千里。在大模型这条道路上,出现了各种形形色色的模型的定义,不论是大模型、产业模式,还是小模型等等,都以一种全新的概念姿态出现。但细看其具体的应用,其中的很多功能接近同质化,尤其是在TO B领域的应用上,同时更不乏基于开源进行开发的“套娃”模型。
于此之中,落地场景和产品也更是寥寥无几。
差距是客观存在的,不论是对标微软的Open-AI,还是谷歌的PaLM 2,中国的大模型目前仍需要更大程度的在底层能力上的补齐,而透过谷歌的这次发布会,未来中国大模型的路该朝向何方?或许会有一些答案。
一、PaLM 2:有望超越GPT-4
PaLM 2作为谷歌最新大语言模型,是本次发布会的重磅消息。
据美国科技媒体记者Federic,“PaLM 2将应用于谷歌最新发布的Bard聊天工具中,成为OpenAI的ChatGPT的最大竞争者。此外,PaLM 2也是今天宣布的大部分AI功能的基础模型。”
多语言性:PaLM 2 在多语言文本方面进行了严格的培训,涵盖100多种语言。这极大提高了其理解、生成和翻译各种语言的能力,包括理解习语、诗歌和谜语。
推理:PaLM 2有广泛的数据集,包括科学论文和网页。因此,它展示了在逻辑、常识推理和数学方面的改进能力。
编码:PaLM 2在大量公开可用的源代码数据集上进行了预训练。这意味着它擅长Python和JavaScript等流行的编程语言,还可以用Prolog,Fortran和Verilog等语言生成专门的代码。
与其他大语言模型一样,搭建PaLM 2需要耗费大量的时间成本和资源。然而,PaLM 2能应用于C端和B端两种环境,企业客户可根据特定领域的数据进行微调,以便在特定场景下执行任务。
如今,PaLM 2已应用于谷歌的25个功能和产品,包括Google Bard聊天机器人和Google Workspace协同文档。
其中,PaLM 2的最轻版本Gecko足够小,可以在手机上运行,每秒处理20个tokens,大约相当于16或17个英文单词。不过,虽然PaLM 2虽然在推理和语言等方面取得了较为显著的成绩,但它仍面临着技术挑战和大模型的共性问题。
比如一些专家已经开始质疑创建语言模型所使用训练数据的合法性。因为这些数据从互联网上抓取,通常包括受版权保护的文本和盗版电子书。而谷歌在PaLM 2的升级中,也并没有披露更多关于数据源的细节。
另外,AI“幻觉”问题也未得到解决。大模型擅长编造信息,谷歌研究副总裁Zoubin Ghahramani在接受The Verge采访时表示,在这方面,PaLM 2是对早期模型的改进,“从某种意义上说,我们正在投入大量精力不断改进基础性和归因指标”,但他指出,在AI领域,打击人工智能产生的虚假信息,“还有很长的路要走”。
二、大模型会“魔法”——编辑器和创作器
在这次发布会中,两个具体的功能成为焦点。
第一个是Google推出的人工智能驱动的魔法编辑器(Magic Editor)。用户可以在照片的特定部分进行复杂编辑,并填补照片空白。
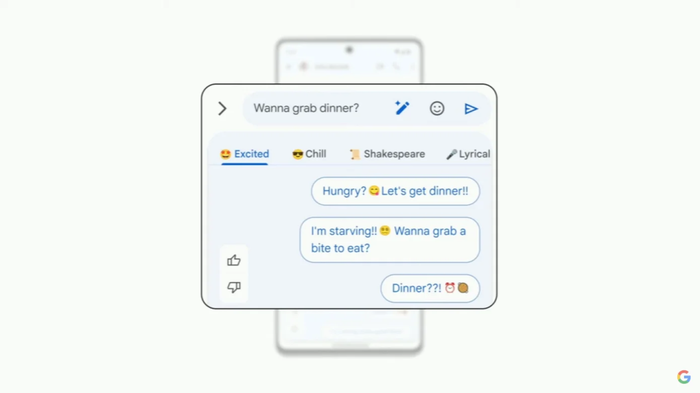
另一个功能是魔术创作器(Magic Compose),利用生成式AI帮助人们撰写个性化信息。它可以以不同风格撰写信息,甚至可以莎士比亚风格的信息。
基于AI大模型,谷歌地图还发布「沉浸式路线视图」,在洛杉矶、旧金山、纽约、伦敦、阿姆斯特丹、柏林等15个城市进行试点。用户可在导航时使用该功能,提前看到整个路线的动态街景视角,包括交通模拟、自行车道、复杂十字路口、停车等详细信息。
除了谷歌的“魔法工具”和谷歌地图,还有更多基于PaLM 2的AI新功能。比如,在音乐方面,谷歌推出了MusicLM,可将文本转化为音乐。假设你在举办一个晚宴,通过简单输入“晚宴的深情爵士乐”,该工具即可创建歌曲的多个版本。
此外,Google Workspace也实现了AI办公功能。据了解,谷歌将在180多个国家和地区提供英语版本的Bard聊天机器人,而且还推出了对日语和韩语的支持。在不久的将来,Bard会支持40种语言。
在此基础上,谷歌还通过Bard与Adobe合作,开发了艺术生成功能。
在谷歌文档的侧面,将会出现一个新面板——Sidekick,可以帮助用户在写作时阅读并整理文档,根据上下文提供与内容有关的建议,可以对标Notion。
同时,优化的还有自身的搜索。据了解,谷歌正在试验一种由人工智能驱动的对话模式。用户搜索时会看到建议的后续步骤,可以根据对话模式进入建议的下一步。此外,谷歌还引入了“观点”过滤器。
三、AI生成代码,Codey比肩GitHub Copilot
本次,Google发布的代码生成工具「Codey」,是对GitHub Copilot的一个回应。Codey经过专门培训,可以处理与编码相关的提示,并且还接受过处理与Google Cloud相关查询培训。

Codey是基于谷歌的PaLM 2大语言模型的编码工具。谷歌表示,该工具是在大量获得许可的开源代码、大量内部谷歌代码、公司所有代码示例及其参考应用程序的基础上进行训练的。
谷歌表示,该模型是在大量获得许可的开源代码、大量内部谷歌代码、公司所有代码示例及其参考应用程序的基础上进行训练的。开发人员能够直接在他们的IDE聊天框中与Codey聊天,或者在文本文件中写评论,让它生成相关代码。
对于Codey,谷歌的愿景是,它希望通过这种聊天机器人技术,在不久的将来,开发人员可以管理他们在谷歌云上的所有服务,包括部署和扩展应用程序。
四、谷歌云的“三大基础模型”
从Transformer架构到PaLM 2,除却GPT模型之外,实际上,谷歌一直保持领导者地位。
在本次在Google I/O 2023大会上,Google Cloud又迈出了一大步,对代码生成模式和模型调整都做出了改善。以下为本次更新的三大基础模型:
Codey,文本到代码模型,帮助开发人员完成代码、生成和聊天
Imagen,文本到图像模型,帮助客户生成和编辑高质量图像,满足任何业务需求
Chirp,语音转文本模型,用于翻译、沟通和交流
这些基础模型可通过API访问,也可以在生成式AI Studio中的UI进行调整,或部署到数据科学笔记本。
值得一提的是,独特的调优功能能够结合人工反馈来训练,可用于微调基础模型的奖励模型。这对于医疗、金融和电子商务等行业有着十分重要的应用。
写在最后:
今年,Google I/O大会之所以备受关注的一个焦点在于,其基于自身的大模型,谷歌做到了将固有的全部产品接近重塑的程度,这种重塑不单纯是产品逻辑上的重塑,更是能真实落地、真实使用的重构。
比如面向C端的办公文档,比如与Adobe结合的图片设计,比如文生图、图生文、文生音乐等等,相较于Open-AI的发布,谷歌的大模型表达更加具象和入微,也更贴近人们生活的场景。
而在B端业务上,更是如此。
不论是其在低代码/无代码上的进一步迈步,还是基于谷歌云三大模型的梳理和拆解,再或者是在机器人智能的结合下进行智能交互、智能指令的新企业模式,都展示出谷歌可以将AI大模型真正应用到企业生产和TO B场景中。这种应用不是单纯的AI算法,而是真正基于大模型的特定业务表达。
从这些视角来看,这也更是中国大模型应该去践行的。
在过去的多年时间里,中国在移动互联网方面处于领先地位,这种领先体现在互联网的广泛使用、智能手机的极高普及率,这些领先最终沉淀出的就是真实有价值的数据,而这也是如今百度腾讯阿里京东以及其它企业做大模型的基础。
但在数据训练之上,基于软件层面和基于开发层面的真实场景的表达,如今却甚为少见。
或者说,单纯的比较参数量级仅代表的是大模型本身的能力,而并不是其能赋能产业的能力,谷歌和微软的成功应用也在昭示这一点:大模型应该和真正的场景结合,基于此才能释放更大的想象力和价值。
不论是谷歌,还是微软,在其大模型发布后,都能看到的是其矩阵内的产品的迅速跟进,对中国大模型企业而言,也更应该强化大模型的应用层,在具备微信、淘宝等一众全球移动互联网时代最有明星价值的产品的土壤上,在这个制造业发达,供应链众多,数字化转型迫切的环境里,中国本土的大模型具备的价值将更大,其能搅动的市场变化也会更为剧烈。
对中国大模型厂商而言,市场期待的,也恰是这些真正可落地的应用和实践。这些实践可以在社交,在电商,在低代码,在供应链,也更可以在一个个中国产业数字化转型的新洼地。
评论