

文|FBIF食品饮料创新 Viola
做出一款爆品有多难?
对于很多品牌来说,这是一个一问就会有一把辛酸泪的问题。花了大量时间心血精心开发的产品进入市场后却没有一点水花;花了很多钱做投放,销售额还没成本高;其他产品莫名其妙火了却因为备货不够错过流量;上个月流行的趋势下个月就过气,上产品的速度赶不上热点过气的速度......在现在想要找到一个不“卷”的赛道很难,产品同质化严重、消费者注意力分散,创新还能怎么做?
我们或许可以从AI身上寻找到新的解决方案。
过去几十年,每次AI都是靠击败人类出圈。但到了2023年,AI的出圈方式却是靠“生成内容”与人协作。
现在的生成式AI不仅有像ChatGPT一样可以与人对话的,快速生成包装创意的Midjourney,还有可以根据概念和关键词生成一百多种产品配方的N-Wing Star......


不仅如此,在生成式AI的协助之下,E=MC²也被重新定义为了个性化新消费时代,收益属于那些能够持续有效洞察和满足用户需求的企业。对于食品品牌来说,E代表企业的收益(Earning),M是商品(Merchandise),C就是消费者(Customer)。而C²则代表了消费者在产品创新和终端购买的双重影响力——根据目标消费者喜好设计产品,再把产品卖给目标消费者。
人货场的关系或将在生成式AI的迭代中被改写。这可能是颠覆性变革的开始,命运的齿轮从此开始转动。
生成式AI是怎么做到的?品牌应该如何与AIGC磨合?我们一起从下文探索。
一、像“人”一样思考的AIGC,都有哪些能力?
2016年,衔远科技创始人周伯文博士在IBM纽约总部提出人工智能应分为狭义人工智能、广义人工智能以及通用人工智能三个阶段。而这三个阶段分别代表的是人工智能不同的学习能力。
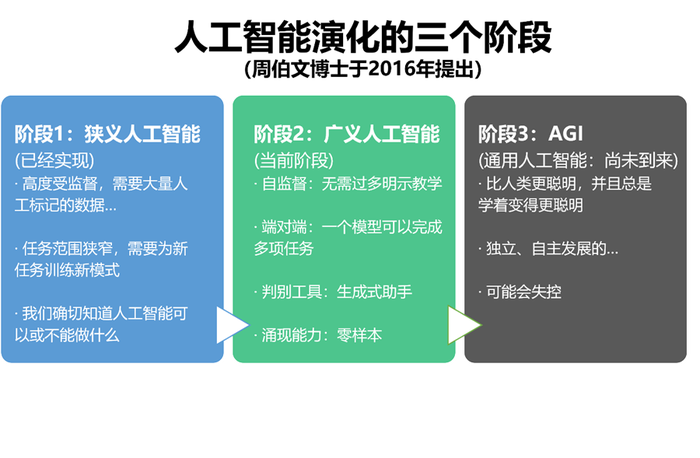
在狭义人工智能时代,企业使用各种小模型(比如神经网络)为实际工作提供的帮助是建立在大数据基础上的分析预测(高度受监督)。它的优势在于人类永远可以清晰地知道这个人工智能模型能做什么以及不能做什么。食品饮料行业很早就在使用狭义人工智能中的多种模型去做不同的事:自动化生产、食品监控、安全检测......
狭义人工智能看起来已足够厉害,为什么还要继续迭代呢?
狭义人工智能的局限在于它只能根据训练的模型执行任务,需要根据不同的场景部署数百个模型。但它没有办法理解这些文字背后的意义,或者是不同语境之下的潜意思。但在博大精深的中华文化里,只是一个简单的“啊”字在不同声调下都能表达出各种不一样的意思,这对于狭义人工智能来说更是琢磨不透了。
而现在的生成式AI已经不再只是停留在狭义人工智能能做的“已知、求解”的关系,而是走上了一个“未知、得解”的道路。
它开始产生“涌现能力”,即通过预监督或自监督的方式去完成自我训练,由此具备了此前从未有过的“零样本学习能力”。与过去的判别式AI不同的是,它变成了一个能与人类共创的“生成式助手”(比如根据输入的关键词生成食品包装创意图片)。

在这里我们要提到一个近期大家很熟悉的词语——大模型。
相较于小模型来说,大模型会使用更大规模的数据进行训练,以此来保证数据的广泛性和多样性,帮助模型学习准确而全面的知识。不仅如此,大模型可以储存、表示更多的信息特征和关系,由此会更加灵活,表达和学习能力也会更强。
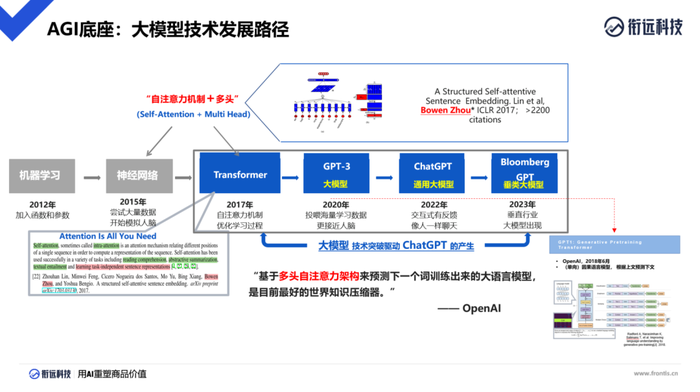
据周伯文介绍,目前我们熟知的ChatGPT的大模型来自于GPT,而GPT是Transformer发展的一个分支。在整个人工智能的发展中,Transformer是引发这一轮AI浪潮的重要里程碑。
Transformer相较此前神经网络最大的不同在于,它具备了一个叫做“多头自注意力”的机制。它的存在让AI第一次能够做到“一目十行”、长期记忆并理解长文本内的因果关系,从而产生各种更强大的推理能力。
下面我们简单理解一下什么是多头自注意力机制。
对于人类来说,视觉注意力机制是我们特有的大脑信号处理机制。我们可以通过快速扫描图像来获得重点关注的目标区域。以下图为例,图上由红到绿依次表现了人类视觉对这张图不同程度的注意力分配。其中红色区域表示视觉系统更关注的区域,如:婴儿面部、标题、文章首句、产品名。
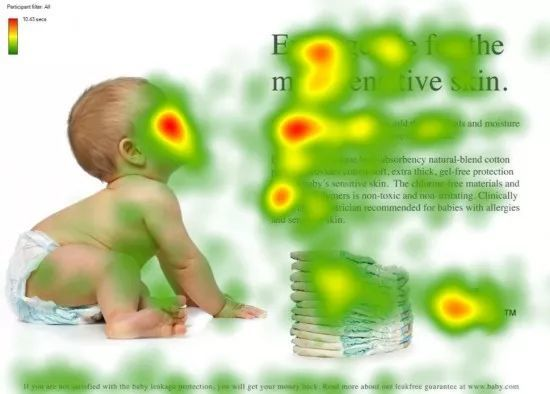
而人工智能中所用的注意力机制本质上和人类的视觉注意力机制相似,核心也是可以从众多信息中选择出来对当前任务更关键的信息,我们可以把它理解为“聚焦”。自注意力机制(Self-Attention)就像是一个信息检索表,通过计算权重来标明相互关系、嵌入上下文信息。以英汉翻译为例,当信息在编码器和解码器中走了一遭时,输出的内容不仅要有单词上的一一对应,也能满足输入内容的上下文关系。而多头的概念就像我们拼乐高玩具,要先用零件拼成头、胳膊、腿等部位(多个不同的注意力层),最后再综合组装形成成品。
而这种上下文学习能力意味着机器具备了隐含概念的推理能力,我们来看一个实例理解。首先,下面这个问题的答案是什么?

事实上,“是”的背后可以跟很多词,逻辑都是成立的。

但如果我们此时给这个填空题前加上两句话:

机器可以识别爱因斯坦和德国人、甘地和印度人之间的关系,从而判断出来玛丽居里后应该跟的是国籍信息——“波兰人”,这就是隐含概念的推理能力。
不仅如此,大模型还具备思维链的能力,可以根据指令对数学题、应用题进行解答。
比如“小明原本有5个网球,之后他又买了两罐,每罐有3个网球,他现在有几个网球?”如果这时只是告诉AI大模型答案是11个,那么当用户继续提问“小明有23个苹果,如果用20个做果盘,又买了6个,小明现在有几个苹果?”时,AI大模型很可能无法进行正确推理而答错。
但是,如果用户对第一个问题的答案给出更清晰的计算推理过程作为提示,比如“小明开始有5个球,新买的2罐网球每罐是3个一共6个,5+6=11,所以答案是11个”,那么再问后面的苹果问题,AI大模型就可以按照同样的推理过程去生成,从而得出正确的答案。
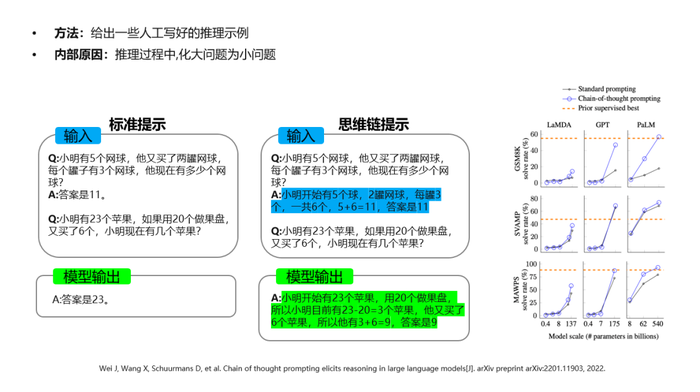
在这种能力的加持下,AI大模型可以完成多跳推理,即“通过从A到B、B到C、C到D的推理,直接完成从A到D的推理”。
如果对答案不满意,用户可以通过大模型的指令微调能力进行“人机磨合”。这个能力可以让AI大模型根据人的价值观去调整自己的输出逻辑,从而做到“知错就改”。假如用户让大模型给一个6岁的小孩解释什么是登月工程,它马上就可以找到多种答案,比如:
以物理学来解释万有引力(答案A);
站在历史角度介绍美苏冷战导致的登月(答案B);
用天文学说明月球是地球的卫星(答案C);
或是从人的美好愿望出发讲述月球上有嫦娥、有玉兔,所以人类想去月球(答案D)等等。
但是,大模型并不知道其中哪一个答案最适合6岁的小孩,所以需要为它引入人类反馈机制做强化学习:通过人工打分,找到最适合6岁小孩的回答方式。当这一系列人类反馈给到AI大模型后,它就可以举一反三,并迅速学会类似问题该如何回答。
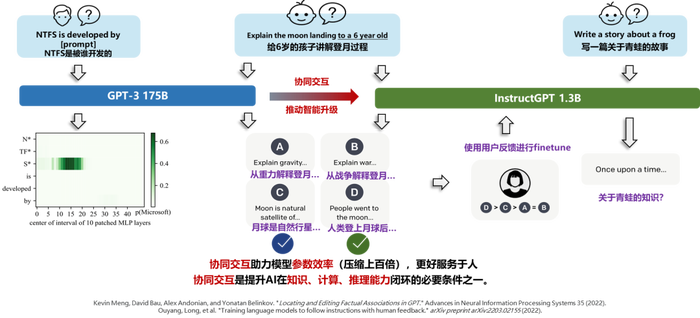
那么,当AI大模型拥有了涌现能力、上下文学习能力、思维链能力以及根据指令进行微调的能力,它能给食品饮料行业带来什么?
二、用AIGC打造爆品的可行性有多高?
在产品创新这条路上,企业们一直在摸索。前几年新消费浪潮之下,我们能看到市场上涌现了许多或新奇或有趣或怪诞的产品。有一些产品顺应浪潮而生,一直走到了现在,也有产品只是在浪潮中昙花一现,很快便不见了踪影。
那么“有把握”的创新可以借助生成式AI来实现吗?
“生成式AI可以通过预测下一个词,去理解消费者和商品体验之间的对应关系。”周伯文在FBIF2023现场如是说道。
在笔者的理解中,这个过程其实和现有各大平台正在做的“打标签”逻辑相似,生成式AI可以把一段消费者反馈拆分成不同的词组然后进行关系匹配,以此来推导出什么样的产品参数、材质、文化符号、功能等等可以打动哪一类人群的消费者。
起初这样的逻辑让笔者不禁想起了电商平台的“千人千面”推荐机制,但如果品牌已经可以依托千人千面机制将产品推荐给合适的消费者了,为什么还需要用生成式AI再做千人千面的产品呢?
答案的关键词还是:消费者。
里斯战略定位咨询全球CEO、中国区主席张云在接受一次采访中提到,产品创新有两种,一种是技术上和产品事实的创新,另外一种则是认知创新。在现实情况中,我们不难发现有许多企业在做产品创新时停留在了技术与事实层面的创新,但却忽略了认知层面的创新。不过,笔者认为认知层面的产品创新并不是指我们要去做一个从来没有出现过的产品,为消费者创造需求,而是要在已有认知里面去寻找还未被完全解决问题的领域去开发产品。但想要靠人力做到彻底了解消费者并不现实,生成式AI的涌现能力,似乎是为此而生的。
这一次生成式AI要做的,不再是把已有的货推送给被匹配的人,而是从一开始就根据目标人群开发匹配他们的货。这可能意味着产品试错率下降以及研发成本下降。
据周伯文介绍,他将AI大模型的能力定义为5D全生命周期:机会洞察(Discover)、爆品定义(Define)、方案设计(Design)、驱动研发(Develop)以及营销转化(Distribute)。如果想要实现人类和AI的高效互动,大模型必须同时具备通用能力和相关领域的专业性——情商+智商+品商。
这意味着大模型不仅能够处理海量的信息、寻找到不同词段之间的概率关系、对语言有理解能力、能根据人类的指令去纠正错误,还要能够理解消费者反馈背后的情绪,做到对商品的深刻理解。
不仅如此,每个企业还可将过去积累的数据与大模型进行结合,包括企业经营、管理、运营、培训等,以此构建专属定制大模型底座,训练自己的Product GPT,完成5D全流程的数字化和智能化。在这个新的框架下,所有的数字化和流程都将沉淀在对话平台上,由其调用不同的后台数字化工具。
不仅是产品研发,生成式AI在营销界也能搅动风云。
AIGC做的营销内容可以称得上是提前预判消费者的喜好。当其和现有各大平台的产品推荐机制结合起来时,这种互补的关系会让营销效率发生变化。
对于平台来说,无论他们怎么优化推荐算法,核心目的就是提高转化率和成交率,他们会通过给用户和产品进行双向的标签匹配来尽可能提高消费者的购买决策概率。所以假如我们搜索某品牌酸奶时,我们不仅会看到该产品,也会在推荐页面中看到和它相似的产品。平台解决的是:有了产品如何推荐给想买它的人,也就是触达。
对于品牌来说,只是让产品触达消费者还不够,如何让他们看见产品就会有消费冲动是要在更前端解决的问题。生成式AI可以结合现有消费者对各品类产品的反馈,分析出消费者核心在意的产品因素以及会影响他们购买的条件,以此实现在准备阶段就做好千人千面的营销文案及图片。
而这种千人千面的内容能够应用到的不仅是在公域流量里抢关注,还能在私域流量里进一步提高消费者体验,甚至可以通过数据的不断学习迭代,向上倒逼产品做到更匹配消费者的需求和习惯。
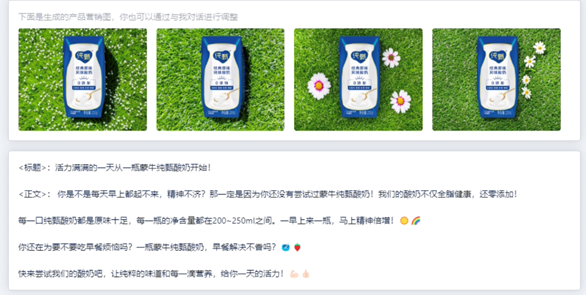
不过,说到营销投放,我们不得不把KOL的影响力纳入讨论范围。一篇好的种草推广,核心是要让人产生消费冲动,这份冲动可以来自于具有渲染能力的文案、可以是精美的图片、甚至可以是一种消费者看到关键词就能联想到的对更美好生活的想象和期盼。但仅仅只是做好内容还不够,品牌们通常会倾向于选择有一定粉丝基数的KOL进行投放,看中的便是他们极强的影响力和引导能力。
对于影响力较小的KOL来说,好的文案是必须条件。但对于影响力大的KOL来说,他可能只需要说一句“姐妹们,买它”就能让产品卖到断货。具有强影响力的KOL或者明星带来的销量固然诱人,但并非每一个品牌,尤其是新锐品牌,都能承受其背后的成本。
“我们之前用AI写的内容做过AB test,直接与KOL进行竞争。结果发现AI写的这种千人千面的营销文字的转化率会比KOL组合整体的文字转化率高30%。”周伯文在采访中回忆道,“对于品牌来讲,大家都会考虑到成本效益。假如我现在用一半的钱投入到AI里,就能达到和找十个顶级KOL代言一样的转化率,品牌也会做出自己的选择。”
在周伯文看来,现在的时代肯定会存在号召力,但我们也确实进入到了一个消费者越来越个性化的时候。对于品牌来讲,AIGC此时就能成为他们打造品牌IP去促进购买转化的有力帮手。
三、品牌如何理解并拥抱AIGC?
无论是哪一种技术的发展对于行业来说都是新的生产力。在科技快速变革之际,企业家们都需要做好准备去拥抱AIGC这个新型生产力。
在FBIF2023圆桌讨论上,蒙牛集团首席数智官李琤洁提出了企业应该做好的三项准备:
第一,企业要积累有足够量级的内部知识。不一定是结构化的数据,大语言模型的出现使得非结构性数据也拥有了更多的应用可能,但无论如何,企业要有自己的知识银行(企业自有数据),才能构建出适配企业自身的大模型应用。
第二,企业要对技术的使用做好合规方面的准备。不同行业的监管力度不同,比如金融行业就非常敏感,是强监管领域。因此,企业需要对积极关注政策变化带来的影响,才能既快又稳地应用好AI技术。
第三,企业要具备根据应用场景去匹配模型的能力。短期来说,显著影响AIGC应用效果的是prompt engineering的能力;但从长期出发,能否有一套自动把复杂事务解构化的能力,对企业来说尤为重要。大模型其实各有特点,其本身的知识量、理解力、生成能力、推理能力、处理多任务能力,甚至价值观导向都会是不一样的。所以应用的时候,要选择不同类型的模型在不同的场景里面进行安排。对企业来说,要有综合性的了解、要有区别性的试验,然后才能做好模型和场景的匹配。
那么,AI大模型生成的内容可靠吗?这个问题可能是阻碍许多企业深度拥抱AIGC的关键。
对于使用过ChatGPT的人来说,有时会发现它所表现出来的成果颇有“外行看着像内行,内行看着纯外行”的感觉。
“生成式AI不仅仅是生成一个东西直接拿给人用,而是让它以Copilot(Copilot一词源于飞行术语,指副驾驶员。在飞行过程中,Copilot是协助主驾驶员操作飞机的人。放到人机协作中来理解的话,AI承担的就是类似Copilot的角色,我们可以通过和它对话来获得信息。比如让它进行信息提炼总结等。)的角色去和人进行交互、对话,来理解业务场景和业务需求。”周伯文在FBIF2023营销创新论坛上分享道,“我们要把所有理解变成生成式内容,再交给人来判断。在这样的反复迭代过程中,我们可以通过这样人机协同的机制来促进生成式AI在产业的落地。”

“诺贝尔经济学奖得主丹尼尔·卡尼曼有一本非常著名的书《思考,快与慢》,里面提出两种思维决策模式:系统1是根据大脑快速决策,系统2是经过慎重考虑来决策。这两种模式非常适合现在人工智能的落地方式,人类员工负责做系统1的决策,因为人容易做,对专业要求也没有那么高。系统2对专业性要求很高,现在生成式AI能把大部分系统2的工作给做了。”周伯文进一步分享道。
四、结语
我们不得不承认,在当下AI大模型还很难一次性满足所有需求。但是,我们不能忽略的是,现有的深层次AI已经具备的涌现能力和人工反馈机制,能够帮助他们在沟通中与人类之间的磨合越来越好。这就像交朋友一样,我们从来不能指望能够遇到一个不需要交流就能全身心契合的灵魂伴侣,但我们可以通过持续的沟通交流来打造一个最懂我们的好帮手。
训练AI大模型的这条路上,需要产业的更早加入和赋能。
参考来源:
[1] 水论文的程序猿,预训练语言模型的前世今生,博客园,2022年7月12日
[2] 玉堃,Transformer:注意力机制(attention)和自注意力机制(self-attention)的学习总结_注意力机制和自注意力机制,CSDN博客,2022年9月6日
[3] 中国消费品牌创新窘境何在?|营销人说,第一财经YiMagazine,2023年4月26日
评论